Generative engine optimization strategies: How to show up on LLMs (full guide)

AI search is no longer a side experiment. It is fast becoming a core part of how B2B buyers evaluate vendors. In the last year, many marketing leaders have opened their CRM dashboards and spotted something surprising: conversions attributed to ChatGPT, Perplexity, or Gemini. At the same time, their Google traffic has softened. Buyers are not only asking LLMs for answers, but also trusting them to make recommendations.
This shift is happening faster than most anticipated. According to interviews we conducted with B2B decision makers, executives openly admitted they now use ChatGPT to shortlist companies before making purchases. These were the same questions they used to ask peers or communities just a year ago. Now, the LLM is the first stop.
For B2B marketers, this is both a challenge and an opportunity.
The challenge: no one grew up learning how to “rank” on ChatGPT. The opportunity: the playbook is still forming, and early adopters who master generative engine optimization strategies will win disproportionate pipeline.
If you want the fundamentals first, start with the AI Search Optimization (AISO) Guide.
Why traditional SEO doesn’t translate
The instinct for many marketers is to assume that good SEO automatically sets them up for AI search visibility. That assumption is wrong. Our research at Chosenly, spanning over 100 bottom-of-funnel (BoFu) keywords across industries, shows that the overlap between Google recommendations and ChatGPT recommendations is less than 30%.
SEO is a popularity contest: the more backlinks, authority, and search volume you command, the higher you rank. AI search is not. LLMs are not optimizing for authority metrics in the same way; they are optimizing to provide fit. They answer: Based on the facts I’ve found, which vendor seems the most relevant recommendation?
That means you need a different generative engine optimization strategy. The goal isn’t just to be seen. It’s to be recommended when buyers ask for advice. For a side-by-side breakdown of how the channels differ, read AI Search Optimization vs SEO: What You Need to Know in 2026.
The four prompt types that matter most
When people think about showing up in AI search, they often assume any mention is valuable. But in practice, the majority of LLM interactions don’t drive revenue.
Many are curiosity-driven like asking ChatGPT to explain a concept or top-of-funnel, where a buyer is still far away from making a decision.
The real impact comes from bottom-of-funnel prompts: the kinds of questions buyers ask when they’re about to select a vendor, choose between alternatives, or validate whether your product is a fit.
These are the moments when ChatGPT, Perplexity, or Gemini stop being research tools and start being decision engines. At Chosenly, we’ve broken these into four core categories:
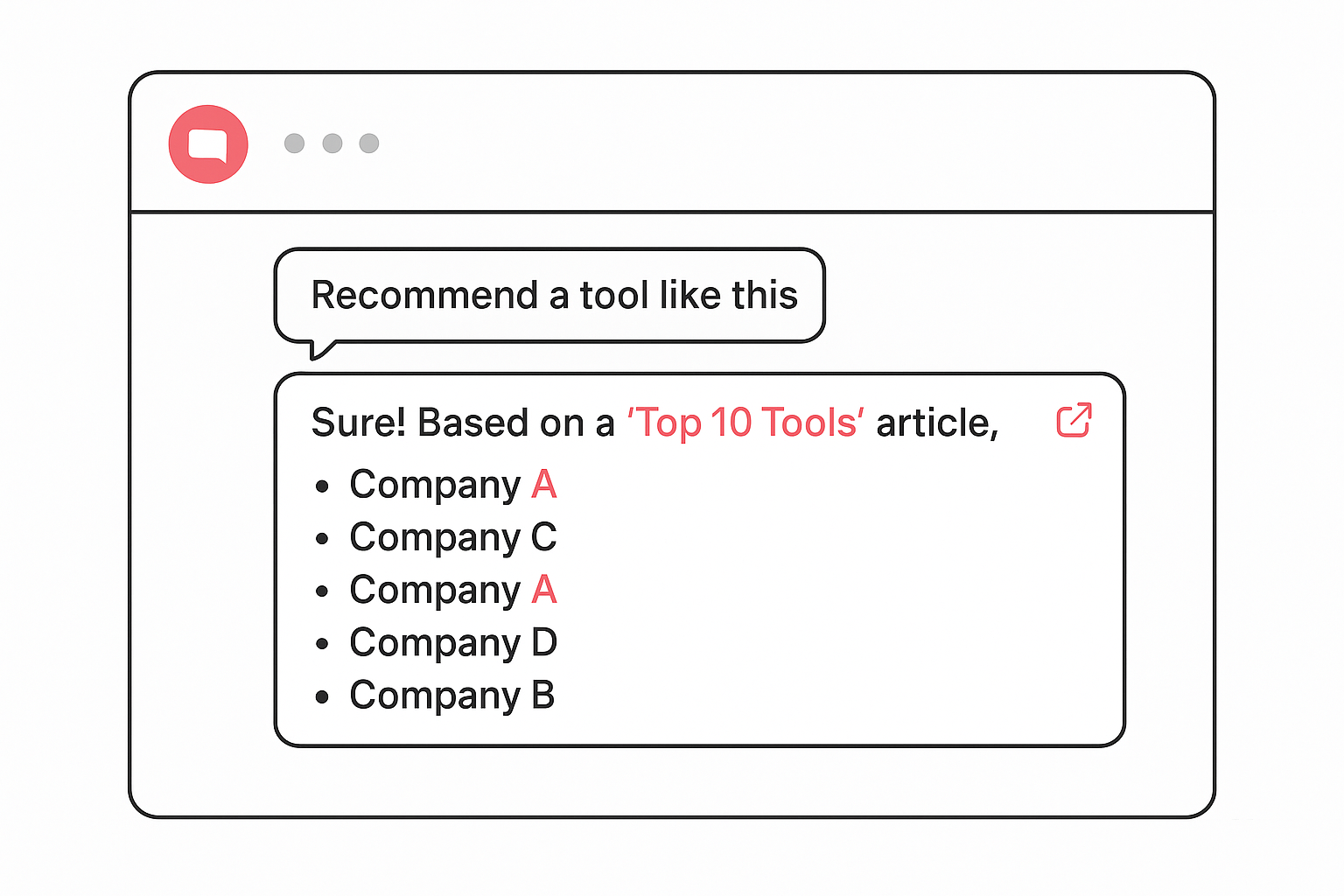
1. “Recommend software like this”
This is the most direct recommendation prompt, and it comes in two flavors: simple and contextual.
- In its simplest form, a buyer might type:
“Recommend HR management software for a mid-sized company.”
- In its contextual form, the buyer adds specific requirements:
“I run HR for a logistics company in the US with 300 employees. We need strong compliance features and customizable leave policies. What HR software should I choose?”
The second is far more common in practice. Unlike Google, where queries are short, LLM prompts often mirror full conversations. The buyer “briefs” the model with their constraints, and the model filters accordingly.
If your company doesn’t show up in this category, you’re excluded from the earliest vendor lists buyers will actually act on.
2. “What platform fits my job to be done”
Here, the buyer isn’t naming a category. They’re describing the problem they need solved. This is where job-to-be-done thinking overlaps perfectly with generative engine optimization strategies.
For example:
“I need tools that can help me reduce my AWS bill.”
“Which agencies can scale our paid ads from $50K/month to $200K/month?”
The buyer has already framed the outcome. The LLM now acts as a consultant, surfacing the platforms or services that align best. This category is critical because it catches intent that would never have shown up in Google keyword data. Many of these “do this for me” prompts are net-new searches LLMs have unlocked.
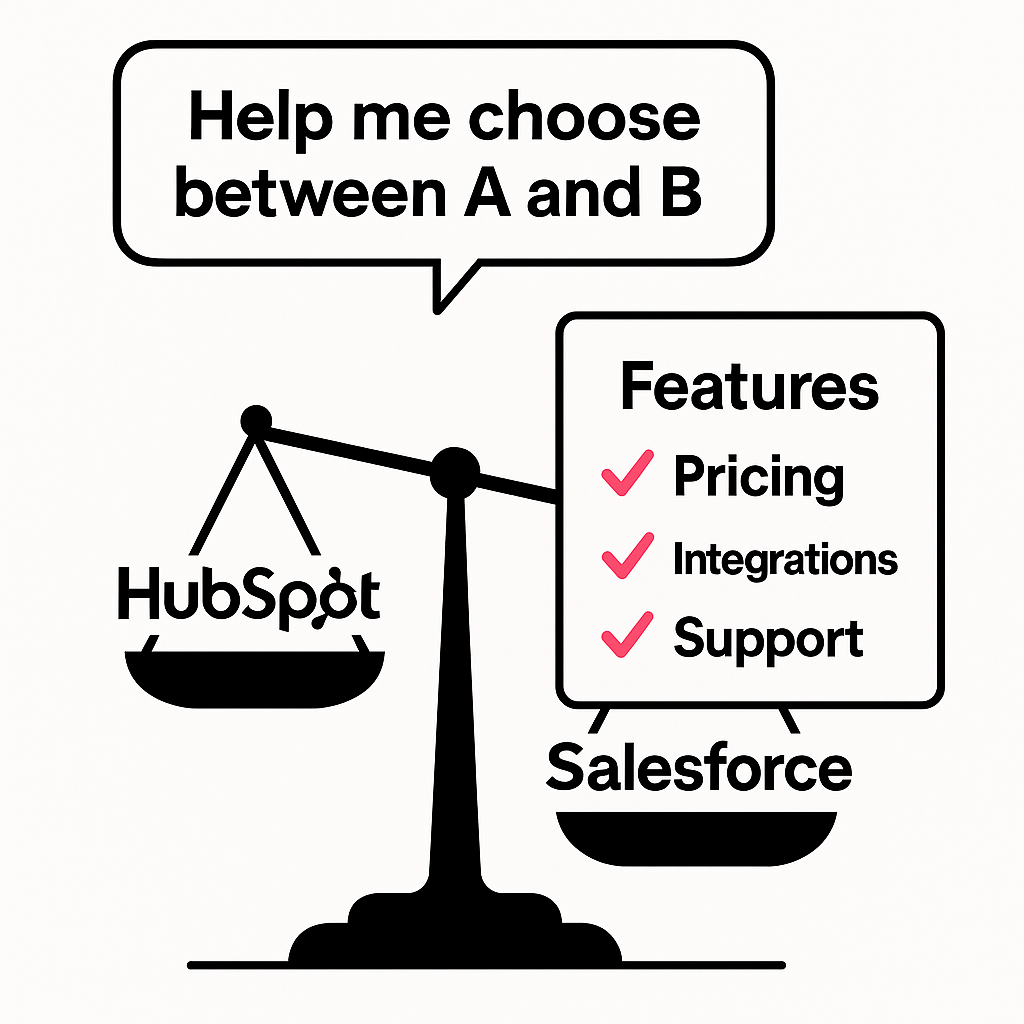
3. “Help me choose between A and B”
This is the comparison stage. The buyer has already shortlisted two or more options and wants help breaking the tie.
Example prompts include:
“Is Deel better than Dovetail for global payroll?”
“Should I use HubSpot or Salesforce for a mid-market SaaS?”
These are classic evaluation moments. If you’re not present here, you’re not in the room when the decision is finalized. What makes this type especially important is how heavily LLMs lean on structured comparisons: feature tables, pricing transparency, integration details, and support claims. The companies that publish these elements in clear, quotable formats will win disproportionate share of “A vs B” recommendations.
4. “Tell me about [Company Name]”
Finally, there’s the direct query about you. Buyers who have already heard of your brand whether through ads, referrals, or communities use LLMs as validation tools.
They might ask:
“Tell me about Chosenly.com. Is it a good fit for improving AI search visibility?”
“What do reviews say about G2 versus Capterra?”
This category matters because it’s where misrepresentations and hallucinations often appear. If ChatGPT is misquoting your pricing, misidentifying your ICP, or crediting your competitors with features you have, it will directly shape buying committees’ perceptions.
Fixing these errors and ensuring your narrative is consistent across sources is one of the most important generative engine optimization best practices.
The three-step framework for generative engine optimization
At its core, showing up in LLMs is not about luck, hacks, or throwing endless content online. It’s about executing consistently across three steps: identifying the right prompts, knowing where the models pull their evidence from, and making sure you look like the best choice when that evidence is weighed.
The framework sounds simple, but this is where most companies stumble because while the concept is straightforward, the operational detail is demanding.
Step 1: Identify the prompts that matter
The first mistake teams make is treating AI search like Google search: they assume the same keywords translate. They don’t. In Google, volume rules. If a keyword has 10,000 monthly searches, that’s attractive. In LLMs, there is no “search volume” data to chase. Instead, what matters is whether a query type triggers a recommendation.
This is why we anchor our work around bottom-of-funnel (BoFu) prompts. As we covered earlier, these include:
Recommendation prompts: “Recommend a tool like this”
Job-to-be-done prompts: “What can help me reduce AWS bills”
Comparison prompts: “Is X better than Y”
Direct brand prompts: “Tell me about [Company]”
These are the questions where ChatGPT and other LLMs act as advisors, not just encyclopedias.
The practical job here is to map your category’s BoFu prompts. That means running dozens of real-world queries in ChatGPT, Perplexity, and Gemini, and capturing which types of answers actually mention vendors. Then, narrow your focus to the prompts where:
- Companies are being named, and
- Those companies look like your direct or adjacent competitors.
This becomes your “prompt set,” the list of opportunities where LLM recommendations can directly affect your pipeline. Without this, you’ll waste months optimizing for irrelevant questions that never generate deals.
Step 2: Understand where LLMs are pulling data from
Once you know the prompts that matter, the next step is to study the sources the LLM is citing or paraphrasing without citation. Unlike Google, where links are clear and rankings are ordered, AI search is opaque.
But it’s not impossible to reverse-engineer.
In practice, LLMs lean on a mix of:
Listicles: “Top 10 [category] tools” style articles that provide ready-made vendor lists.
Review sites: G2, Capterra, Gartner, TrustRadius, and niche directories.
PR articles: Trade press, news outlets, and funding announcements.
Third-party blogs: Medium posts, LinkedIn Pulse articles, even Reddit threads.
YouTube videos: Demos, explainers, and reviews are increasingly cited.
Your own site: Especially support, pricing, integration, and industry pages.
The work here is about forensics. For each prompt, track down what sources the model references. If it quotes a stat, trace it to the article. If it lists five tools, find which listicle those names came from. Over time, patterns emerge.
For example, in HR tech we’ve seen listicles dominate, while in martech, review sites carry more weight. In new categories, even LinkedIn Pulse posts can be surprisingly influential.
This source map becomes your to-do list. It tells you where to publish, where to get mentioned, and where your absence is costing you recommendations. Without this, you’re flying blind.
Step 3: Look like the best-fit recommendation
Finally, once the right prompts and sources are mapped, you need to ensure that when your company is included in the model’s dataset, you come out looking like the logical choice. This is where criteria mapping comes in.
LLMs make recommendations based on two things:
- The explicit criteria buyers type into their prompt (budget, integrations, company size, compliance needs).
- The implicit criteria the model “believes” define a good product in your category (ease of use, quality of support, pricing transparency, breadth of features).
If you’re strong on support but the model doesn’t have enough evidence to see it, you won’t get credit. If your ICP is SMBs but your reviews skew enterprise, the model will misclassify you. And if your competitors publish transparent pricing while you hide it, the model may default to them as the “safer” recommendation.
The operational fix is to audit each criterion and ensure you have credible, quotable evidence for it. That could mean adding a detailed support page, publishing a pricing philosophy, running an SMB-specific review program, or issuing a PR piece on compliance.
Each of these gives the LLM “receipts” to justify recommending you over competitors. For page-level execution guidance, use How To Optimise Your Website For ChatGPT (And Other LLMs) In 2026.
This is also where you fix misrepresentations. If an LLM claims you serve enterprises when you don’t, you need to re-weight reviews and clarify ICP on your site.
If it claims a competitor has better support just because they raised $20M, you need to publish detailed support guarantees that neutralize that perception.

Why most teams fail at execution
On paper, the three steps are simple: find prompts, find sources, look like the best choice. But each step hides an iceberg of work.
Identifying prompts requires running and tracking dozens of queries across multiple LLMs. Mapping sources requires painstaking citation-tracing. Looking like the best choice requires alignment across content, PR, reviews, and product marketing.
That’s why most teams stop at “visibility monitoring” tools that show mentions but don’t help you act. The companies that win are the ones who operationalize these steps into a repeatable system.
That’s exactly what we built Chosenly to do: turn what looks like an overwhelming new channel into a structured, executable program
Step 1: Getting found in the right places
The first and most basic requirement of generative engine optimization is visibility. If large language models can’t find credible information about you, they won’t recommend you no matter how innovative your product is, how many customers you serve, or how strong your support is.
LLMs don’t make leaps of faith. They synthesize from evidence. If the evidence isn’t there, you don’t exist.
This means the first real battle is not about persuasion, it’s about discoverability. You need to make sure your company is present in the specific sources LLMs already reference when answering the kinds of prompts that drive pipeline.
The first strategy to achieve that is to...
GEO Strategy 1: Create content that LLMs actually cite
One of the most important generative engine optimization strategies is ensuring that LLMs find your content credible enough to reuse in their answers. But not all content is treated equally. Generic SEO blogs stuffed with keywords won’t cut it. LLMs disproportionately rely on structured, fact-rich, and well-organized content. That means your mandate isn’t “publish more” but “publish different.”
The formats most often cited include:
- Listicles that summarize tools in a category.
- Comparison blogs that break down vendor differences.
- Support, pricing, or integration pages with explicit, quotable details.
- Case studies with contextual facts (company size, stack, outcomes).
This is where a good generative engine optimization strategy shifts the job of content teams. Instead of chasing volume, your focus is on filling information gaps that LLMs currently struggle with.
1) Pick the right thin-competition topics
Start by mapping the exact “top X tools”/“best tools for [job]” queries relevant to your category. Then prioritize the ones with thin citation competition topics where LLMs have fewer strong sources to draw from.
How Chosenly helps: In the dashboard, enter your seed terms. The system automatically turns them into prompts and shows a citations column you can use as a competition proxy. Topics with fewer citations are easier to influence. Pick a handful of these to go after first.
2) Reverse-engineer what the LLM already quotes
For each target prompt cluster, identify which exact URLs the model is pulling from and which sentences it’s reusing. Treat this like a content blueprint: if a specific phrasing or fact pattern keeps getting injected into answers, you need a semantically equivalent (or stronger) version on your own properties.
How Chosenly helps: For any prompt cluster, the dashboard shows:
- The exact articles/URLs being referenced.
- The specific statements the model lifted (e.g., “experts recommend …”).
- The most relevant page on your site (if any) that could be optimized or flags when you’ll need a net-new page
Use this to assemble a content brief that mirrors the format LLMs prefer for that query (often a listicle), plus the facts they keep citing.
3) Build the right content asset (even if you’re not the domain expert)
If you’re not yet an expert on the subtopic (say, AI rank tracking nuances), do internal interviews to extract original perspective instead of summarizing what’s already on the internet.
A practical interviewing playbook:
- Record a short session with a subject-matter stakeholder to close information gaps around the target topic.
- During the call, relentlessly ask what / why / how about every claim until you uncover concrete steps, examples, and constraints.
- To save prep time, keep your research stream close at hand (e.g., a LinkedIn feed tuned to relevant posts). Quick spot-checks in ChatGPT before the call (≈10 minutes) help you aim your questions.
- Decide when to stop by checking against a pre-planned structure: if the winning pages include FAQs, a comparison table, or specific best-practice sections, ensure you’ve gathered enough detail to fill those.
Transcribe the call and use the transcript as your raw source of truth.
How Chosenly helps: Upload transcripts and align them with the prompt clusters and citation gaps already identified in the dashboard. This ties your interview insights directly to the evidence the LLM is currently missing.
4) Draft fast in an AI workspace, then polish by hand
Create a drafting workspace where the model writes in your voice and with your facts:
- Feed in brand tone materials (e.g., prior LinkedIn posts), internal docs, and sales-call transcripts so the model learns your ICP and messaging.
- Paste the interview transcript and give explicit drafting instructions: include primary and secondary keywords at least once, keep the title within limits, use the target structure (listicle with sections/FAQ/table), and expand into paragraphs (not bullets).
Generate a V1, then manually edit:
- Expand thin sections with the interview detail you captured.
- Convert compressed bullets into full, readable paragraphs.
- Add images and screenshots
- Insert sources generously; quotable, evidence-rich content is more likely to be reused by LLMs.
How Chosenly helps: The product rolls this end-to-end flow into the toolchain:
- It selects what to write (thin-competition prompts).
- It surfaces which facts and statements are being cited elsewhere so you can include equivalent or better evidence.
- It generates a V1 draft with the right directives (e.g., how many stats, sections to include, length, expansions).
- You keep only the final human polish step.
5) Publish, then verify that it’s working
Ship the page (new or optimized) and validate that it starts getting used by LLMs in recommendation answers.
How Chosenly helps: Track any URL (your site or third-party platforms like Medium/LinkedIn Pulse). The dashboard monitors whether and where the page is being cited across prompt variations, so you see if your content has become part of the model’s answer set.
6) Why this strategy moves the needle
- You’re targeting recommendation moments, not generic awareness.
- You’re writing where the model is thin, so new evidence has outsized impact.
- You’re matching the exact format and claims the LLM already trusts, while adding unique, interview-derived insight it couldn’t find before.
- You’re closing the loop with tracking to confirm inclusion in answers.
This process helps you with getting found on LLMs.

GEO Strategy 2: Listicle outreach for LLM visibility
LLMs frequently assemble recommendations from third-party “Top 10/Best of” articles. If Company A appears in ten listicles and Company B in only one, the model is far more likely to keep surfacing Company A. In many B2B categories, listicles dominate citations; in newer niches you may also see landing pages, PR sites, or specific blogs show up. You can’t influence others’ landing pages, but you can influence listicles.
Which is why One of the most reliable ways to influence how large language models recommend software is to get your company mentioned in listicles.
Step 1: Spot high impact listicles
The Chosenly dashboard identifies exactly which listicles are cited by LLMs and how often, so you know where to prioritize. It also distinguishes between high-frequency citations (pages referenced in 100+ answers) and low-frequency ones, giving you a priority list based on real impact data
Step 2: Build a tight target list you can realistically work
Depending on the industry, you may see anywhere from eighty to eight hundred possible pages. Apply an 80/20 filter and keep a working list to the top twenty to thirty percent by impact, which typically means no more than one hundred targets at a time. This concentrates effort where it will shift LLM recommendations fastest.
How Chosenly helps: Start from the priority list inside the dashboard rather than a manual Google dive. Filter out pages that already include you, and keep the list synced as you add or remove targets.
Step 3: Prepare your outreach assets
Write a short opener that consistently earns replies: “Hey [Name], I came across your listicle on ‘[title].’ Would you be open to including [your company] in the listicle? Happy to discuss how I can make it worth your while.”
Keep it deliberately open-ended so the author can indicate what they value. Send this note as a personalised connection request on LinkedIn to the authors of the listicles.
Expect roughly thirty percent of authors to accept your personalized connection request and around forty percent of those to reply. Many treat inclusion as a sponsorship or backlink decision and quite a few have sponsorship language ready; treat this as a negotiation starting point rather than a blocker.
How Chosenly helps: Store your opener as a reusable template inside the product so your first touches stay consistent. Track which value exchanges close fastest in your category so you can lean on what works.
Step 4: Execute outreach in a light daily cadence
Have one person send the first touches and work the replies in about an hour a day. The constraint is not sending messages; it is negotiating a handful of threads at once while you wait for authors to respond. Keep the pipe to roughly one hundred live targets so you don’t create more follow-ups than you can handle.
How Chosenly helps: Use the target list view to mark stage and status per page and to keep all conversations moving without losing track.
Step 5: Negotiate to one of four predictable outcomes
Plan on less than five percent of wins being free inclusions; call it one or two per one hundred targets. Expect fifteen to twenty percent of responders to accept non-monetary swaps such as reviews or recommendations, or a reciprocal feature in a listicle you publish, which has proven consistently effective. Use backlink barter when the author frames the decision as a backlink play; offering a sixty-plus Domain Authority backlink you can place elsewhere typically costs you one hundred and twenty to one hundred and fifty dollars while feeling valuable to them. For paid inclusions, budget around two to three hundred dollars per placement after negotiation; ignore outlier quotes you can’t justify.
How Chosenly helps: Log the chosen exchange type against each target and keep basic cost math visible so you don’t overspend on low-impact pages
Step 6: Model the numbers and set a realistic budget
From one hundred first touches, a practical working model is thirty-five replies. Out of those, expect two free inclusions and roughly six non-monetary swaps at zero cash cost, five backlink barters at about one hundred and fifty dollars each for a total of seven hundred and fifty dollars, and five paid inclusions at about three hundred dollars each for a total of one thousand five hundred dollars. Your approximate out-of-pocket is therefore 2250 dollars for around eighteen total inclusions, excluding internal time. That volume of placements is typically enough to materially shift which vendors the model cites in recommendation answers.
Treat this as one of your core generative engine optimization techniques alongside content creation and reviews.
How Chosenly helps: The dashboard ties each new placement back to the prompt clusters it influences, so you can see which spend actually moved citations. This closes the loop on generative engine optimization best practices.
Step 7: Publish, verify the mention, and capture details
When an author agrees, make sure the final article actually includes your name, the correct URL, and the positioning you want. Record the live URL and the date it went live so you can measure time-to-citation and keep expectations aligned.
How Chosenly helps: Attach the live URL to the target in your list and mark it “Track” so the system can watch for appearance in LLM answers across prompt variations.
Step 8: Account for slower refresh cycles and nudge indexing
New inclusions used to show up in LLM answers within days. Refresh cycles now tend to run in weeks and are edging toward months. A lightweight, anecdotal nudge is to ask the same prompt from multiple accounts after a placement goes live. Seeing the same source referenced repeatedly may help the system notice it faster, but treat this as a test rather than a guarantee.
How Chosenly helps: Because you can press “Track” on any URL: your site, Medium, LinkedIn Pulse, or third-party listicles you can see when an inclusion actually begins showing up and in how many answers, rather than guessing.
Step 9: Iterate by impact and compound your citations
Revisit your list monthly. Spend more time and budget on listicles that influence many answers and less on the long tail. Add new high-impact targets that emerged since the last pass. As inclusions stack up, the model is more likely to surface your company in “top tools” responses by default. This compounding effect is exactly why outreach belongs in any set of best generative engine optimization strategies.
How Chosenly helps: The platform continually shows which pages and page types are gaining or losing influence in your category so your next sprint always starts where it will matter most.
Step 2: Extending reach beyond your site
One of the biggest mental shifts marketers need to make in generative engine optimization is letting go of the “my website is the only home base” mindset. Traditional SEO rewarded you for optimizing your own pages: metadata, backlinks, schema, site structure. AI search doesn’t care about that in the same way.
When ChatGPT, Gemini, or Perplexity generates an answer, it pulls from a corpus of references it already trusts. Those references may include your website, but just as often they include third-party mentions: an industry blog that featured you in a “Top 10” list, a customer review left on Capterra, a PRNewswire release, or even a Reddit thread where someone casually recommended your product.
This means your web presence matters far more than your website. Every credible, digital breadcrumb you leave whether you published it or someone else did becomes potential training or inference data for LLMs. If your company’s name, features, and differentiators appear across multiple surfaces, the model gains more “confidence” in recommending you. If you only update your own site, you’re playing on a single surface while competitors spread across the board.
This is where many teams fail. They pour resources into polishing their homepage and blog while ignoring the ecosystem of touchpoints models actually read. That’s why we push clients to treat distribution and redundancy as core parts of their generative engine optimization strategy.
Let’s break down what that looks like in practice.
GEO Strategy 3: Repurposing BoFu content onto third-party platforms
If you’ve already done the work of creating strong bottom-of-funnel (BoFu) content like listicles, comparison guides, recommendation-friendly posts, don’t limit it to your own blog. Publish the same content, or a slightly repackaged version, on LinkedIn Pulse and Medium.
Why? Because we’ve repeatedly seen LLMs cite Pulse articles and Medium blogs as authoritative. These platforms carry domain authority and structure that models seem to favor. By republishing, you give yourself two or three chances to get picked up for the same query. It’s a redundancy play: even if your own blog doesn’t get cited, your Medium version might.

GEO Strategy 4: Leveraging community conversations (Reddit, Quora, niche forums)
Reddit is a particularly rich surface because of its perception as an “authentic” peer-to-peer forum. If your product is discussed naturally in threads especially in niche subreddits like r/SaaS, r/DevOps, or r/marketingautomation, LLMs are more likely to pull those mentions when generating “what people are saying” style answers.
We advise clients to seed reviews or discussions in relevant communities, not as astroturf but as participation. For example, a genuine user case study posted in a subreddit can end up being quoted directly in ChatGPT’s recommendations. Similarly, Quora threads or industry Slack groups that are indexed can carry disproportionate weight.
GEO Strategy 5: PR in outlets LLMs already cite
This is a big unlock: don’t waste your limited PR dollars on vanity outlets. Use data (via tools like Chosenly) to see which PR domains LLMs already reference in your industry. We’ve seen patterns: Reuters, TechCrunch, Axios, niche B2B trades that repeatedly show up in model outputs.
By prioritizing placements in those outlets, you’re literally inserting evidence into the reference set that determines whether you get recommended. A funding announcement, a customer win, or a thought leadership piece can double as a citation engine.
If PR is a lever, use a targeted playbook like PR for AI Search Visibility: Why It Matters & How to Do It Right to prioritize outlets models already cite.
GEO Strategy 6: Repurposing webinars into YouTube explainers
LLMs increasingly pull structured content from YouTube transcripts. If you run webinars, panel discussions, or product explainers, repurpose them into short, clear videos on YouTube. Models can “see” and parse that transcript. When someone asks, “What’s the best tool for improving AI search visibility?” a well-titled and transcribed YouTube video can be the deciding citation that tips the model toward you.
This is an underused channel, but we’ve seen early signals that it works. Think of it as converting every webinar into a permanent, AI-readable proof point.

In short: updating your website is table stakes. Expanding your presence across every credible digital surface is what gets you cited, recommended, and trusted in the AI era.
Step 3: Becoming the recommendation
Getting cited by an LLM is a start. But citations don’t automatically translate into pipeline. Buyers aren’t asking, “List every vendor who exists.” They’re asking, “Which vendor should I choose?”
That’s the difference between being visible and being recommended. In SEO, visibility is often enough. You rank, you get the click, your landing page does the rest. In LLM search, the recommendation happens inside the answer box itself. If you’re not positioned as the best fit in that generative moment, you lose before your funnel even begins.
Why criteria matter
LLMs decide who to recommend based on criteria. Some are obvious because they’re written into the prompt. Others are inferred by the model from context. And still others are assumed, because the model has internal beliefs about what makes a “good” solution.
We group them into three buckets:
- Direct criteria: These are explicitly typed by the user. If a CFO in Europe says, “We have a €50,000 budget and use SAP as our ERP”, the model knows budget and SAP integration are mandatory filters. Fail to show evidence that you’re affordable or integrated with SAP, and you’ll be excluded.
- Indirect criteria: These are inferred by the AI. For instance, if a buyer says they’re based in Germany, the model may infer that GDPR compliance is essential even if the user doesn’t mention it. If your content and reviews don’t make compliance obvious, you won’t be chosen.
- Assumed criteria: These are not stated in the query but baked into the model’s perception of “good software.” Support responsiveness, onboarding experience, transparent pricing, and even brand trust cues (like funding or analyst coverage) can tilt the recommendation. Sometimes these assumptions lead to odd reasoning. For example, one of our clients was marked down by ChatGPT on “support” simply because a competitor had raised $20M. The model assumed more funding meant better support.
Understanding all three is critical. If you only optimize for what’s directly asked, you’ll miss the indirect and assumed layers that often tip the scales.
How Chosenly helps: It is the only platform that surfaces both sets of inputs:
- What your prospects actually type in prompts (budget, integrations, region, industry).
- What LLMs believe matters (good UI, strong support, transparent pricing, compliance).
The platform then shows you where you’re already the top recommendation, where you’re close but under-documented, and where you’re losing.
For example, when ChatGPT downgraded Chosenly’s support in favor of a better-funded competitor, the dashboard highlighted that “funding” was being used as a proxy for support quality. With that insight, the team built a dedicated support page detailing their Slack channels, <1-hour response times, and playbook templates and a comparison table showing why their support was objectively better. Within weeks, recommendations flipped in their favor.
This process is now being productized: the full workflow of mapping criteria, adding required facts, and generating V1 content drafts will live directly inside Chosenly. That means you don’t just learn why you’re being excluded, you get concrete next steps to fix it.
Practical actions that work
Once you’ve mapped criteria, the next step is making them visible and quotable. This is where execution matters:
- Support pages: Create a dedicated page that spells out SLAs, support hours, contact channels, and even your escalation process. Most companies hide this in a helpdesk. Pull it out front and make it easy to cite.
- Pricing philosophy pages: Even if you can’t post hard numbers, explain what’s included, what you charge for, and how ROI is calculated. This transparency is often enough to beat a competitor who simply hides pricing.
- Integration and industry pages: If the model can’t find explicit evidence that you integrate with Salesforce or serve fintech companies, it will assume you don’t. Create one page per integration or per industry, so the evidence is there.
- PR campaigns tied to criteria: Don’t waste PR on generic “we raised money” announcements. Instead, angle stories toward criteria that LLMs weigh. For example, “Company X doubles down on customer support with new dedicated Slack channels” is far more powerful than “Company X raises $5M.”
These assets aren’t just for buyers, they’re for the models. You’re feeding the training and inference layers with the exact evidence they need to justify recommending you.
From citation to recommendation
To summarize, becoming the recommendation is about bridging the gap between being found and being chosen. Citations tell the model you exist. Criteria-aligned proof convinces it you’re the right fit. With Chosenly, you don’t have to guess what those criteria are, you can see them, map them, and act on them systematically.
That’s how you shift from occasionally being mentioned to consistently being recommended. And in generative search, that one shift from “in the mix” to “the pick” can be worth millions in pipeline.
GEO Strategy 7: Handling misrepresentations
One of the most dangerous aspects of AI search is not omission but distortion. LLMs are incredibly confident in their answers even when they’re wrong. A model might state as fact that your platform lacks SOC 2 compliance, misquote your pricing from a 2019 blog post, or suggest that you only serve enterprise customers when in reality your ICP is SMBs.
These errors often fly under the radar. Your sales team may never hear about them because the buyer silently disqualifies you before reaching out. This makes misrepresentation management one of the most critical parts of a generative engine optimization strategy.
At Chosenly, we treat misrepresentations like recurring bugs in software. Each one must be logged, triaged, and resolved. The process is straightforward but requires discipline:
- If the false claim cites your site → fix the page. If ChatGPT is quoting your outdated FAQ or an old pricing page, the solution is immediate: correct it. Don’t just delete the page; update it with clear, current information so the model has something accurate to pull next time.
- If it cites a third-party → request an update or publish corrective content. Suppose the error comes from a G2 review, a comparison blog, or an analyst write-up. Reach out directly to the author or platform to request a correction. If that fails, publish your own rebuttal through PR or a blog that explicitly addresses the error and provides factual, quotable evidence.
- If there’s no source (a pure hallucination) → publish factual, quotable pages. In many cases, models hallucinate without citing anything. For example, “Company X is headquartered in Toronto” when you’re actually based in Bangalore. Here, the best counter is to create factual anchor pages: an “About Us” page with headquarters and team details, a “Compliance” page with certifications, a “Support” page with policies. The more models have structured, quotable text, the less likely hallucinations persist.
The key is consistency. You won’t eliminate misrepresentations overnight. But each fix adds weight to the factual version, making it harder for false narratives to survive across future model refreshes. Over time, the number of errors decreases, and your brand story becomes stable.
Measuring impact
In SEO, you live and die by keyword rankings. But in generative engine optimization, there are no SERPs to screenshot. The metrics are different, and they fall into two categories:
- Citation share: How often your brand is cited in responses to priority prompts.
- Recommendation share: How often you’re not just mentioned but recommended as the top option.
- Reduction in misrepresentations: How frequently errors about your brand appear, and whether they’re decreasing after your fixes.
- LLM-attributed traffic: Visits tagged in GA4 or UTMs from ChatGPT, Perplexity, or Gemini.
- Conversions: Are those visits signing up, requesting demos, or trialing?
- Pipeline: Are they becoming MQLs, SQLs, or closed revenue?
The beauty of this channel is speed. In traditional SEO, results can take 3–6 months. In AISO, we’ve seen LLM-driven traffic double in as little as three weeks after consistent execution. That’s because models frequently regenerate answers, and small shifts in citations or criteria alignment can instantly change recommendations.

Who should own generative engine optimization?
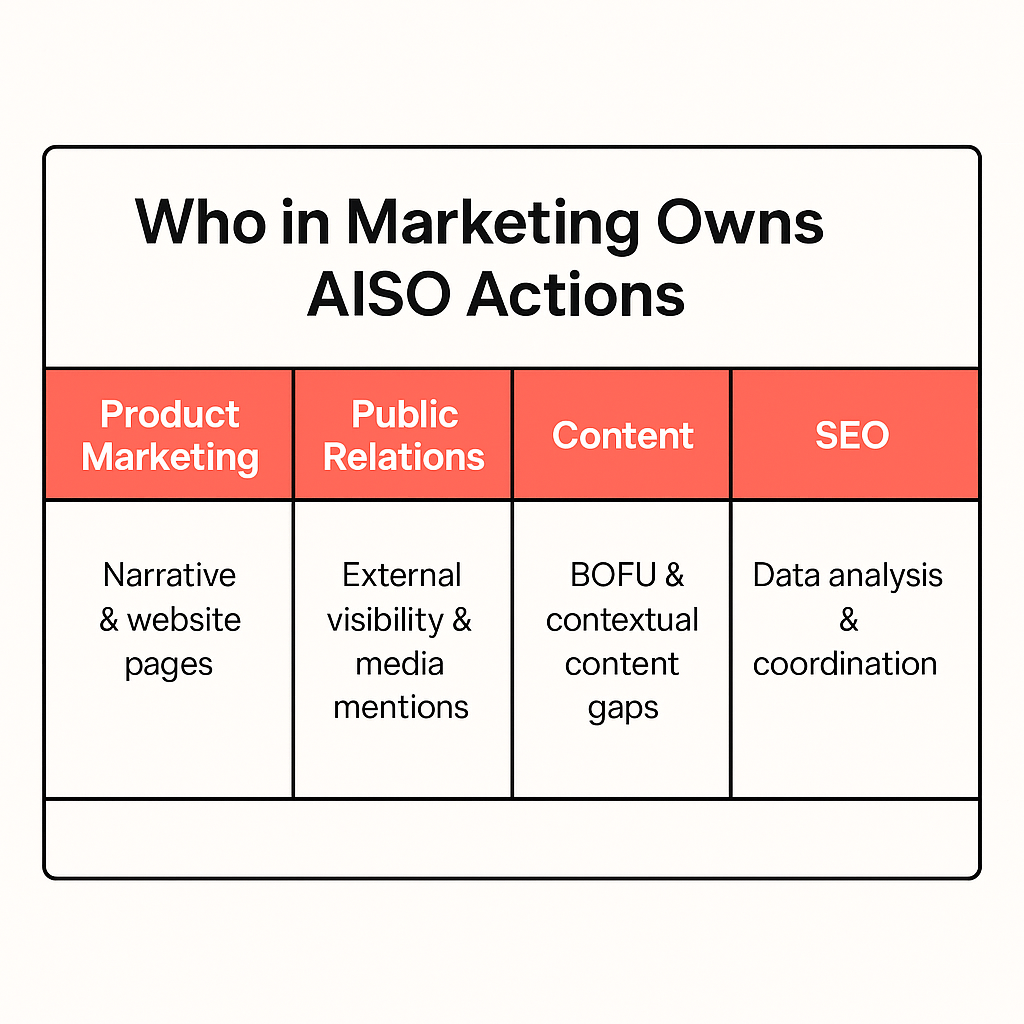
Because this is a new discipline, ownership often feels fuzzy. But execution requires cross-functional alignment. We recommend the following division of labor:
1. Product marketing owns the narrative
They are best positioned to fix positioning issues on-site, restructure messaging, and create assets like pricing, support, and industry-specific pages. If you want to be recommended, your narrative has to match what buyers and LLMs are looking for.
2. SEO teams drive execution
SEOs are uniquely skilled at turning mountains of data into prioritized action and at collaborating across content, PR, and product marketing. Even if they aren’t writing every page, they should quarterback the effort.
3. Content teams build the assets
From listicles and case studies to LinkedIn Pulse articles and Medium posts, they create the raw material LLMs will consume. AISO demands deeper research and subject-matter interviews than generic SEO content.
4. PR teams pitch the outlets
Thy pitch the outlets models cite most frequently Reuters, TechCrunch, niche industry publications. They ensure your differentiators appear in the right places for AI to ingest.
At Chosenly, we’ve argued that SEOs are natural owners of AISO, but the shortage of practitioners who deeply understand both SEO and AI search means this will remain distributed for now.
Generative engine optimization best practices
After hundreds of experiments, we’ve distilled the enduring truths of generative engine optimization best practices:
- Focus only on bottom-of-funnel prompts. That’s where buying decisions are made.
- Create structured, proof-rich content that fills gaps AI can’t answer well.
- Secure mentions in listicles and review sites; they’re disproportionately weighted by LLMs.
- Extend beyond your site: Pulse, Medium, Reddit, YouTube, PR all count as inputs.
- Map criteria and add visible proof where you have a right to win.
- Fix misrepresentations quickly and visibly; don’t let errors compound.
- Measure leading indicators first (citations, recommendations, misreps), then lagging ones (pipeline impact).
Follow these consistently and you’ll not just be seen but recommended.
Conclusion
AI search has changed the rules. B2B buyers now ask LLMs to recommend, compare, and validate vendors, which means the job is no longer to “rank”, it’s to be recommended.
Traditional SEO signals don’t translate cleanly because generative systems optimize for fit based on available evidence, not just authority. Winning therefore comes down to executing a clear generative engine optimization strategy across three steps: identify the bottom-of-funnel prompt types that actually drive deals (recommend, job-to-be-done, A-vs-B, and direct brand queries), understand exactly which sources LLMs pull from in your category (listicles, review sites, PR, Pulse/Medium, YouTube, your own support/pricing/integration pages), and make yourself the best-fit recommendation by publishing visible, quotable proof against the criteria models weigh both stated and unstated.
The teams that succeed treat this as an operational discipline, not a one-off campaign. They create structured, proof-rich content that fills gaps models struggle with; extend beyond their website to build redundancy across Pulse, Medium, Reddit, YouTube, and PR; and fix misrepresentations quickly by updating their pages, correcting third-party sources, and shipping anchor content so models have facts to cite next time.
They measure what matters for generative engines: citation share, recommendation share, and reduction in misreps as leading indicators, then tie it to lagging business outcomes like LLM-attributed traffic, conversions, MQLs/SQLs, and pipeline. Ownership is cross-functional: product marketing leads narrative and key assets, SEO quarterbacks execution, content produces citation-worthy pages and posts, and PR targets outlets LLMs already cite. Follow these generative engine optimization best practices, and you’ll move from occasionally being mentioned to consistently being chosen.
If you’re already seeing ChatGPT, Perplexity, or Gemini in your CRM, now’s the time to double it. Chosenly operationalizes the best generative engine optimization strategies end-to-end from surfacing the prompts and sources that matter to showing the criteria you must prove and helping you ship the assets that flip recommendations.
Ready to turn AI search from a curiosity into a reliable, compounding pipeline source? Let’s map your gaps and build your program.
Book a call here.