How to Rank on Claude: Proven Tactics to Get Featured in Claude’s AI Answers

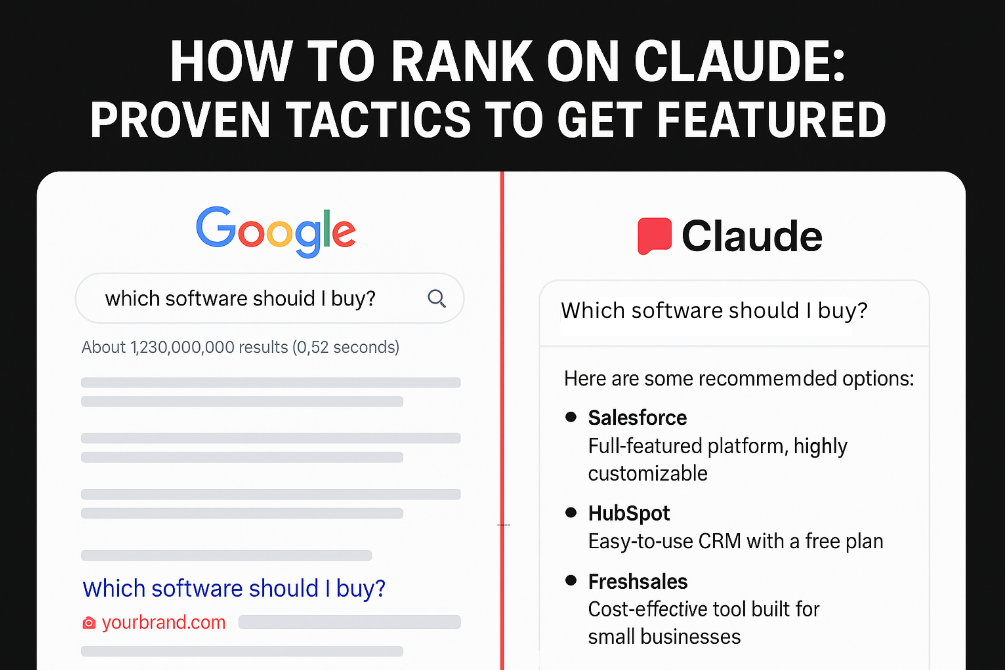
Let’s be honest: nobody woke up one morning thinking, “I need to figure out how to rank on Claude.” But here we are. Buyers now open Claude before they open Google. They type questions they’d normally ask a peer, a Slack group, or a consultant. They don’t click through a dozen blue links. They don’t scroll through Google Ads. They literally ask, “Which software should I buy?” and expect Claude to give them a shortlist or sometimes just a single recommendation.
That flips the search game on its head. We’ve covered why generative search is changing buyer behavior in our blog on Generative Engine Optimization Strategies: How to Show Up on LLMs.
On Google, your job was to earn the click. You just needed to get people onto your landing page and let your funnel take over. With Claude, your job is different. You don’t just want to be seen, you want to be the answer itself.
If you’re not cited or worse, not recommended you’re effectively invisible at the exact moment when a buyer is ready to make a decision.
And here’s the kicker: Claude actually has the ability to fetch real-time information from the web and cite your content by name. That’s a massive opportunity. But it doesn’t happen every time. Whether Claude pulls in external content depends on what kind of question the user asks and whether Claude believes it already has the answer in its internal knowledge.
If the model thinks it knows enough (say, “What is CRM software?”), it won’t even bother looking outside, it just answers from memory. In that case, no links, no citations, no chance for you to show up. But if the query is specific, time-sensitive, or complex like, “What’s the best SOC 2 compliance tool for startups under 200 employees?” Claude will flip on its web search. That’s when your content has a chance to be pulled in, cited, and positioned as the best-fit recommendation.
So “ranking” on Claude isn’t about keywords or domain authority it’s about being present at the exact moment Claude decides to search. And when it does, it’s going to reward the page that’s the easiest to quote: structured, clear, and directly relevant to the question asked.
For a deeper dive into how SEO overlaps with AISO (and where it doesn’t), read our blog on AI Search Optimization vs SEO: What You Need to Know in 2025.”
How to Rank on Claude: Insights From the System Prompt Leak
In May 2025, a detailed version of Claude’s system prompt surfaced online. Hanns Kronenberg analyzed it in depth, with Aleyda Solís amplifying the findings, and for the first time marketers had visibility into the internal logic that governs how Claude decides when to search, what tools to use, and under what circumstances it will surface external content.
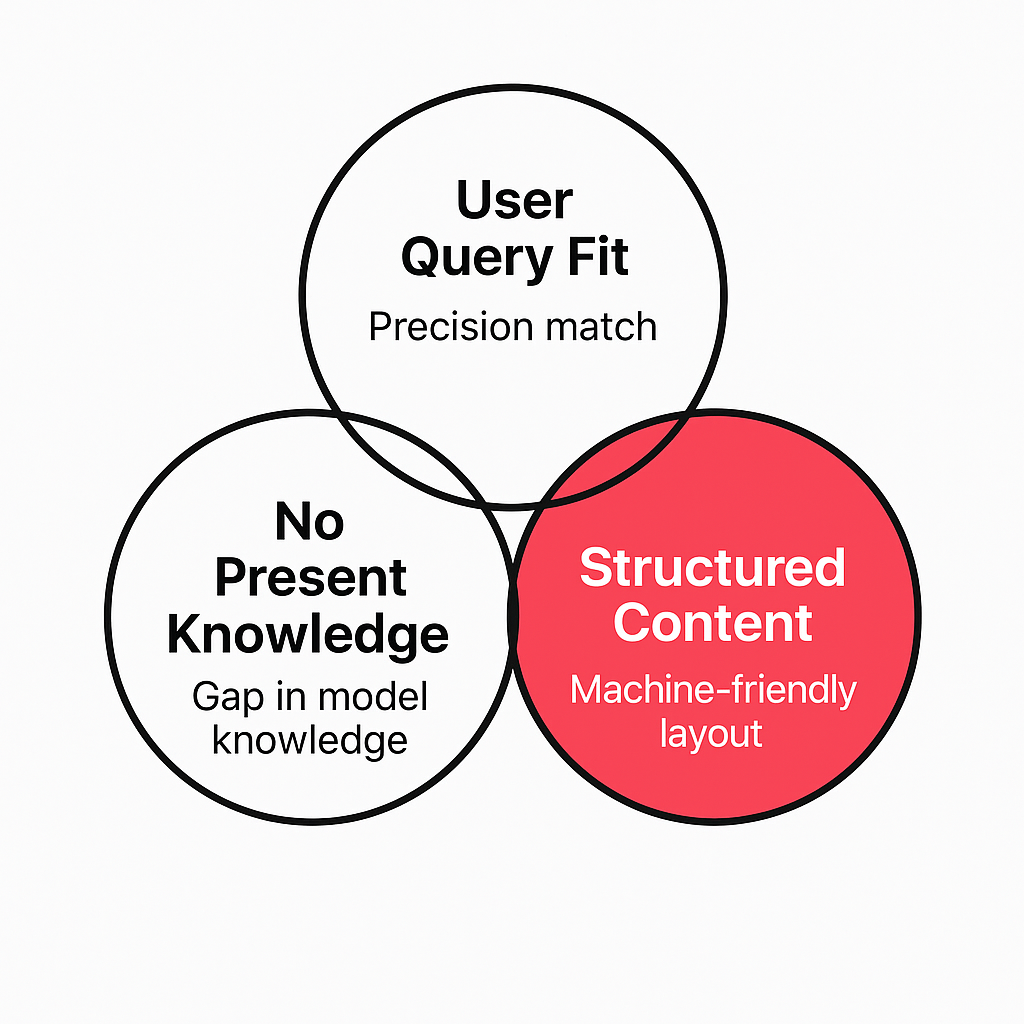
The key lesson distilled from the leak came down to three factors: User Query Fit, No Present Knowledge, and Structured Content.
- User Query Fit means Claude doesn’t reward vague relevance. It evaluates whether your page is the most precise and useful match for the exact user prompt. Generalist content is deprioritised in favour of tightly scoped, query-aligned information.
- No Present Knowledge confirms that unless Claude determines its internal training data is insufficient, it won’t trigger web search at all. If the model can answer confidently from memory, external sources never enter the equation. This makes freshness and uniqueness of content critical.
- Structured Content refers to the way information is presented. Claude favors content that can be cleanly extracted and quoted at the sentence or table level. Long paragraphs, buried facts, or unstructured claims are less likely to be cited because they are harder for the model to repurpose.
Taken together, these insights change the way optimization for LLMs is understood. Visibility is not a function of backlinks or domain authority, it is a function of whether Claude is forced to look beyond its internal dataset, and if so, whether your content is the most query-aligned and machine-parseable option available.
For the first time, SEOs and content strategists have a framework that is not guesswork. Instead of producing content broadly in the hope of being included, they can deliberately engineer material that aligns with the exact conditions under which Claude pulls external sources.
This is the foundation of LLM visibility optimization: understanding the trigger conditions for search, and ensuring that when those conditions are met, your content is both discoverable and structured to be cited.
The 4 search modes
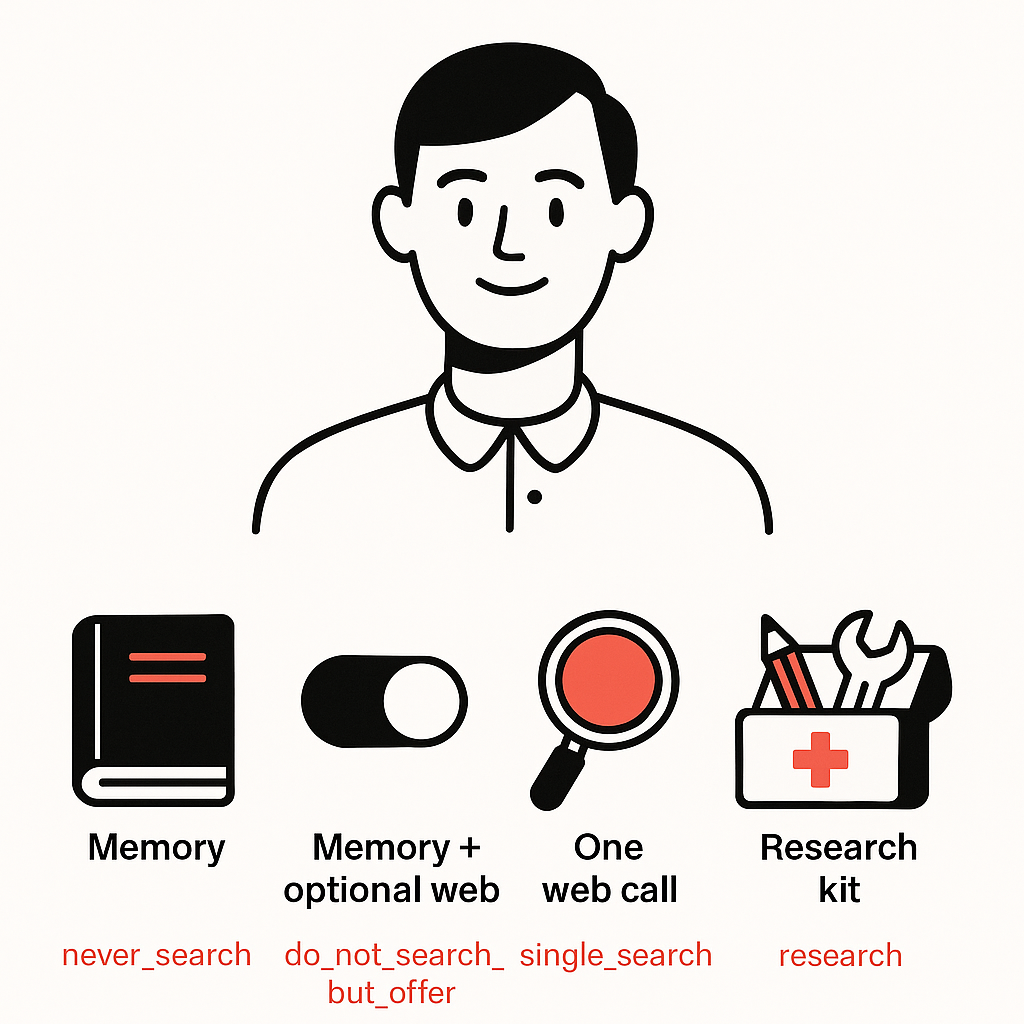
One of the most important things the Claude system prompt leak revealed is that Claude doesn’t treat every query the same. It uses four distinct “search modes” to decide whether it should rely on its internal training data or reach out to the web for fresh information. These modes essentially define when you have a chance of being cited—and when you don’t.
1. never_search
This applies to stable, timeless facts. “Who wrote Pride and Prejudice?” “What is the boiling point of water?” For questions like these, Claude doesn’t waste resources searching the web, it answers directly from its internal knowledge.
The implication for visibility is stark: no matter how good your content is, you simply cannot appear here. If you’re creating content purely around definitions or universally known facts, you’re producing material that Claude will almost never cite.
2. do_not_search_but_offer
This is a middle ground. Claude already has a confident answer, but it knows the information may need updating, so it offers to run a search if the user wants. An example might be: “What is the current GDP of Canada?” Claude can provide an approximate number from memory, but since populations change, it will often add: “Would you like me to check the latest figures on the web?”
From an optimization perspective, this mode is tricky. Unless the user explicitly opts for a search, your content won’t surface. Even if they do, the model often prioritizes official or government sources in these scenarios.
3. single_search
This is where opportunities start to open. Claude uses this mode when the query is simple and factual but outside its stored knowledge, such as: “Who won the Academy Award for Best Picture this year?” It performs one quick search, fetches the answer, and cites a single source.
For SEOs and marketers, this is a visibility window. If your site is the cleanest, most structured, and most up-to-date source of the fact, you can get cited. But you’re competing for a single slot. This is where structured content - short sentences, direct claims, clear tables matters most.
4. research
This is the mode everyone should care about. Here, Claude receives a complex, multi-layered query something like:
“What are the best payroll tools for EU startups with SOC 2 compliance and under 500 employees?” Claude can’t answer this from memory. It needs context, depth, and specificity. So it runs between 2 and 20 tool calls, gathering data from multiple sources, cross-referencing, and then assembling a structured response.
This is where your carefully built comparison pages, compliance-focused industry pages, detailed support SLAs, and integration-specific content become invaluable.
Claude doesn’t just need a snippet; it needs building blocks for a nuanced answer. If your content provides those building blocks in structured, quotable formats, you’re far more likely to get cited—and even featured as the top recommendation.
What this means for your strategy
The real insight is this: you only have visibility opportunities in “single_search” and “research.” Everything else is a dead zone for citations. That changes how you should think about content production.
- Stop wasting cycles on purely informational, “what is X” type content. That’s the territory of never_search.
- Don’t chase marginal visibility in do_not_search_but_offer unless you own the official data.
- Invest heavily in content that answers factual-but-current queries (to win in single_search).
- Double down on structured, detailed, criteria-driven assets that feed into research queries.
And here’s the nuance: optimizing for Claude isn’t about sheer volume. You don’t need 100 blog posts to rank. You need a handful of high-quality, structured, citation-ready assets aligned to the exact conditions that trigger search.
In other words, it’s not about writing more, it’s about writing the right kind of content Claude can’t ignore. And if you’re wondering which agencies are actually helping brands optimize for these new LLM behaviors, check out our roundup of the Top Generative Engine Optimization Agencies of 2025.
Why “authority” doesn’t matter (and why that’s freeing)
This part makes old-school SEOs sweat. For two decades, “domain authority” and “backlink profiles” have been the currency of search. Big brands with bigger link budgets dominated because Google rewarded them for popularity signals.
Claude doesn’t play by that rulebook. In Claude’s world, “authority” as SEOs know it is basically irrelevant. You don’t need a million backlinks. You don’t need to be Salesforce. You don’t need to outspend your category on PR just to climb up page one.
What you do need: structured, copy-pasteable facts.
Claude’s priority isn’t who you are—it’s how usable your content is in response to the query. The system prompt leak made this very clear: when Claude is forced to look outside its training data, it’s not searching for the biggest brand or the loudest voice. It’s searching for the cleanest, most query-fit information that can be slotted directly into an answer without friction.
That means:
- Tables that compare features line by line.
- Calculators that provide fresh, context-specific outputs.
- Support SLAs spelled out in plain text with response times, escalation paths, and coverage hours.
- Pricing breakouts that clearly explain ranges, inclusions, or ROI examples.
- Compliance statements (SOC 2, GDPR, HIPAA, ISO) framed in ways that make quoting unambiguous.
- Comparison charts that distill differences buyers actually care about.
Claude doesn’t link because you’re big; it links because you’re useful. And that shifts the competitive landscape.
For smaller or newer brands, this is liberating. In SEO, you might be drowned out for years by incumbents with massive backlink arsenals. In Claude, if you publish sharper, cleaner, more quotable info than the incumbents, you can leapfrog them in the exact moments that matter when a buyer is asking for a recommendation.
It reframes the optimization mindset: your leverage isn’t in building “authority” for algorithms, it’s in building clarity for buyers and models simultaneously. If you can become THE source that Claude trusts to provide precise, structured facts, you can win visibility even in categories where Google rankings feel impossible to crack.
In other words: Claude flattens the hierarchy. Authority no longer guarantees visibility. Usefulness does.
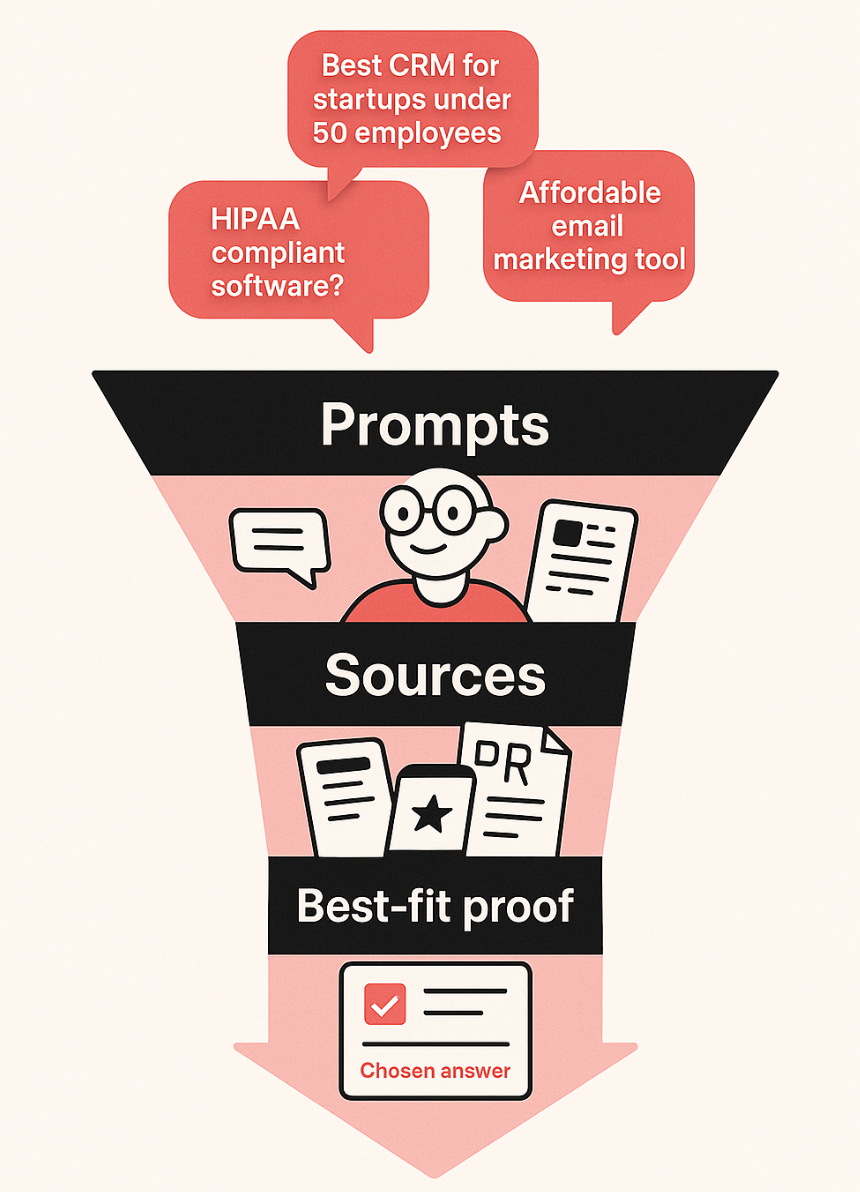
Three steps to win: Prompts → Sources → Best-fit proof
Claude visibility isn’t random. It follows a logical sequence: first, the model has to be asked the right kind of question; second, it has to pull from sources it trusts; and finally, it has to decide which vendor looks like the best recommendation. If you want to consistently show up in Claude’s answers, you need to work deliberately across all three.
Step 1: Identify the BoFu prompts
Not every question a buyer asks will move pipeline. Top-of-funnel prompts like “What is marketing automation?” or curiosity-driven ones like “Explain AI infrastructure like I’m five” rarely produce vendor mentions.
What you care about are bottom-of-funnel (BoFu) prompts, the ones buyers type when they’re actively evaluating solutions. Examples:
- “Which data privacy platform integrates with Salesforce?”
- “Is [Vendor A] or [Vendor B] better for small businesses in healthcare?”
- “Best project management software for companies under 200 employees with ISO compliance.”
Why this matters: without a defined prompt set, you’ll waste months creating content for questions that never lead to vendor citations. With it, you have a clear blueprint of where to focus.
Step 2: Reverse-engineer the sources
Once you know which prompts matter, the next question is: Where is Claude pulling its evidence from?
Unlike Google, which shows you ranked URLs, Claude’s source attribution is fragmented. Sometimes it cites directly. Sometimes it paraphrases without a link. But with enough testing, you’ll notice patterns. Claude tends to lean heavily on:
- Listicles → “Top 10 tools for X” articles, often from SaaS blogs or agencies.
- Review sites → G2, Capterra, TrustRadius, Gartner Peer Insights.
- PR/trade press → announcements, analyst coverage, funding stories.
- Third-party blogs/LinkedIn Pulse/Medium → especially in emerging categories where formal coverage is thin.
- YouTube transcripts → demos, tutorials, comparisons.
- Your own site → especially pricing, support, integrations, and industry-specific pages.
This list becomes your source map, your to-do list of where you need to appear, either by publishing directly (your site, Pulse, Medium, YouTube) or by getting included (listicles, reviews, PR).
We explored how PR plays into this in our blog on PR for AI Search Visibility: Why It Matters & How to Do It Right.
Step 3: Look like the best-fit recommendation
Even if you appear in the dataset, Claude still has to choose who to recommend. And it does so based on three layers of criteria:
- Explicit criteria → Written into the prompt: budget, integrations, region, industry, team size.
- Implicit criteria → Inferred by the model: if the buyer is in Europe, Claude assumes GDPR compliance matters—even if the user didn’t mention it.
- Assumed criteria → Baked into the model’s worldview: good support, pricing transparency, easy onboarding, analyst mentions.
The goal is to eliminate ambiguity. If your competitor has detailed support docs and you don’t, Claude may default to them even if your support is better.
Why this works with Claude
Claude is unique among LLMs because its web answers show citations and its API Citations feature quotes exact lines. That means when you supply the clearest, most copy-and-pasteable facts, you literally increase the odds that Claude will use your sentence verbatim in its response.
Think of your content as Claude’s raw material. The sharper and more structured it is, the easier it is for Claude to pick you as the building block for its answer.
Claude-specific optimization checklist
Use this checklist as your build-sheet. It’s tuned to the way Claude handles web citations and API Citations.
A. Create sources Claude wants to quote
- Comparison pages: “X vs Y,” “Best tools for [use case]” with tables for features, pricing, integrations, SLAs.
- Pricing & support pages: include numbers, SLAs, contact channels, coverage hours, onboarding steps.
- Integration pages: one per system; list capabilities, limitations, setup instructions—not just logos.
- Industry/vertical pages: highlight regulatory fit, data residency, case studies.
- Listicles: publish on your blog and repurpose on Medium/LinkedIn Pulse to increase redundancy.
- YouTube explainers: short, structured videos with transcripts Claude can parse.
B. Secure third-party mentions
- Prioritize high-impact listicles and review sites already cited in Claude answers.
- Run ongoing outreach: negotiate inclusions, swaps, or PR features that align with your BoFu prompts.
C. Make pages citation-friendly
- Use plain-language headings and atomic sentences for key facts.
- Add named anchors (#pricing, #integrations) so excerpts link cleanly.
- Publish HTML + PDF versions for critical assets (comparison sheets, SLAs). API Citations parse PDFs sentence-by-sentence—make them sharp.
- Ensure bot accessibility (no login walls, correct robots rules).
- Add datestamps and version notes for freshness.
D. Fix misrepresentations fast
- If Claude cites your outdated page → update it (don’t 404).
- If it cites a third-party error → request corrections; publish a rebuttal post.
- If it hallucinates without sources → create anchor pages (About, Compliance, Support, Pricing philosophy) with clear facts.
E. Claude-aware writing & formatting
- Write short paragraphs, active voice, direct “you” language.
- Insert evidence blocks: Fact: [stat]. Source: [URL]. Date: [Month YYYY].
- Add FAQ fragments (<50 words) to target BoFu prompts directly.
- Follow editorial guardrails: optimized meta tags, visuals, interlinks.

Measuring success (hint: it’s not rankings)
One of the hardest mindset shifts for marketers moving from SEO to AISO is learning to stop obsessing over rankings. In Google, everything came down to where you landed on page one. Were you in the top three? Did your keyword move up or down this week?
Claude and other LLMs don’t work like that. There is no “position one.” There’s only being cited or not, being recommended or not. Which means you need a new measurement framework.
Here’s what matters:
- Citation share → How often does your brand appear when Claude answers a BoFu prompt? If you’re cited in 2 out of 10 queries, that’s 20% citation share. Track it over time. The goal is consistent presence, not one-off mentions.
- Recommendation share → Being cited isn’t enough. What percentage of those answers actually position you as the best choice? This is the metric that truly maps to buyer influence, because it reflects whether you’re winning the model’s tie-breakers.
- Misrep reduction → Every time Claude gets something wrong about you (pricing, compliance, ICP), it’s a risk to pipeline. Measure how often hallucinations or inaccuracies show up, and whether that number declines after you fix pages, seed reviews, or publish new anchor content.
- Pipeline impact → At the end of the day, the board doesn’t care if you’re cited in Claude—they care if it drives revenue. Use GA4, UTMs, and your CRM to track LLM-attributed sessions. Then follow those sessions through to conversions, MQLs, SQLs, and closed deals. When you can say, “Claude drove 12 demos this quarter”, you’ve proven AISO isn’t a vanity project—it’s a pipeline engine.
This is what separates visibility monitoring from operational optimization. You’re not just checking if you show up. You’re proving that showing up changes revenue outcomes.

Conclusion
Claude has changed the rules of search. Buyers aren’t scrolling through a page of blue links anymore, they’re asking a single question and trusting Claude to give them the right answer. That makes visibility inside Claude responses more than a marketing experiment. It’s the new battleground for influence at the exact moment buying decisions are made.
The recent leak of Claude’s system prompt stripped away much of the guesswork. We now know that visibility depends on three things: User Query Fit, No Present Knowledge, and Structured Content. In other words, Claude only searches when it has to, and when it does, it rewards content that matches the query precisely, introduces new or time-sensitive facts, and is easy to extract at the sentence level.
We also know not every query creates opportunity. Claude operates in four search modes, but only single_search and research unlock visibility for brands. That means it’s not about producing endless blogs or chasing keywords—it’s about building a handful of structured, citation-ready assets that answer buyer questions with clarity and precision.
And perhaps the most liberating shift: authority doesn’t matter the way it did in SEO. Backlinks and brand size don’t guarantee recommendations. What matters is whether you provide quotable facts—tables, SLAs, compliance statements, pricing details—that help Claude assemble a useful, trustworthy answer. For smaller brands, this levels the playing field. Usefulness beats size.
The path to winning on Claude is methodical:
- Identify BoFu prompts that trigger vendor recommendations.
- Reverse-engineer sources Claude relies on for those prompts.
- Publish best-fit proof in a structured, citation-friendly way.
Finally, measure success differently. Forget rankings. Track citation share, recommendation share, misrep reduction, and most importantly, pipeline impact. If you can tie Claude mentions to demos, trials, and revenue, you prove that AISO isn’t vanity, it’s a growth channel.
FAQs
Q1. How to rank on claude?
You rank by being cited and recommended. Not by backlinks or domain authority. Fit the query, add fresh, verifiable information, and structure it cleanly for citation.
Q2. How to appear in Claude answers?
Publish the content formats Claude leans on during single_search or research: structured comparison tables, pricing and support pages, detailed integration breakdowns, and listicles republished on trusted third-party sites.
Q3. How do I optimize content for Claude?
Align with the three core signals from the leak: User Query Fit, No Present Knowledge, and Structured Content. Make every important fact quotable at the sentence level so Claude can lift it directly.
Q4. How do I get Claude to mention my brand?
Be present on the third-party surfaces. Claude already uses: listicles, review platforms, trade press, PR sites. Pair that with crisp proof on your own site - pricing, support, compliance—so you’re consistently seen as relevant.
Q5. How do I get featured in Claude responses?
Cover the full spectrum of explicit criteria (budget, tech stack, team size) and implicit/assumed criteria (support quality, compliance, transparency). Then reinforce those claims across multiple independent sources. The more evidence Claude has to justify recommending you, the more often you’ll be the chosen answer.