How to Rank on Gemini in 2026: Full Guide

There is a persistent disconnect that many teams are feeling. You can execute the traditional playbook - technical SEO, authority building, and disciplined content and still fail to appear when Gemini is asked to recommend vendors. That gap is not a mirage. Traditional SEO rewards signals of popularity; Gemini prioritizes evidence of fit.
In our work at Chosenly.com, across more than a hundred bottom‑of‑funnel prompts, the overlap between Google’s organic winners and large language model recommendations is far smaller than most expect. Buyers now consult AI systems as decision engines. They type fully formed questions and expect a shortlist that reflects their context: budget, region, stack, and compliance without elaborating on every constraint. If Gemini concludes that a competitor is the safer recommendation based on the evidence it can retrieve, the loss happens before a click. The only durable response is to manage the evidence that the model can see and reuse.
Understanding why the old playbook underperforms clarifies the path forward. Google’s ranking systems lean on authority proxies: backlinks, domain strength, and historical signals. But if you want to rank on Gemini, you need to know that Gemini seeks to satisfy fit. It scans the web for explicit and implicit criteria such as support responsiveness, pricing clarity, integration depth, compliance posture, and onboarding speed, and it favors statements that are concise, verifiable, and consistent across sources.
A sentence on a support page, a paragraph on a review site, a line in a well‑maintained listicle, or a timestamped claim in a PR article can each become part of the answer. When your strongest facts are buried in PDFs, scattered across landing pages, or phrased inconsistently, the model cannot justify recommending you. In practice, “fit” is the intersection of what the buyer asks and what the model believes matters for your category. Some of this is stated in the prompt (“we’re in the EU and use SAP”), some is inferred from context (“GDPR likely applies”), and some reflects the model’s priors about what good software looks like (transparent pricing, responsive support, sensible onboarding). Your task is to publish evidence that covers all three layers and to place that evidence in multiple, trusted locations so the model does not have to guess on your behalf.
The Four Prompt Types That Move Revenue
1. The recommendation moment
This is where early shortlists are formed and where most visibility wins actually begin. In the simplest case a buyer asks Gemini to recommend a tool for a category, but in practice the prompt often arrives with a great deal of context: company size, tech stack, budget ceiling, region, compliance obligations, even preferences like whether a dedicated CSM is required or if live chat support is expected during local business hours. Gemini evaluates those constraints against what it can verify about each vendor.
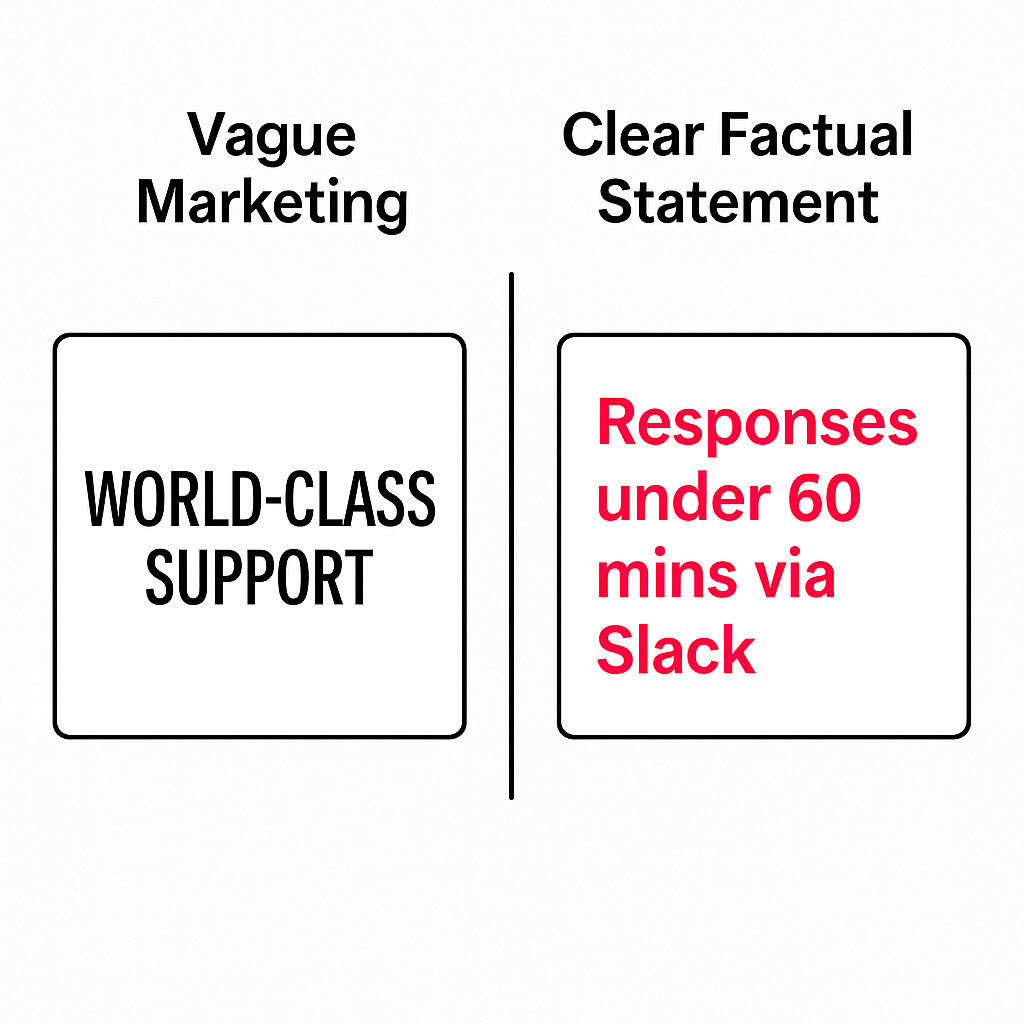
That means the brands that publish clear, crawlable statements about who they serve, which integrations are first‑class, what their support response targets look like, and how their pricing is structured are far more likely to be included.
If your site leaves these questions to implication -“enterprise‑ready,” “world‑class support,” “flexible pricing” the model has too little to justify choosing you.
The practical response is to state your fit in unambiguous language and place it in obvious locations: an integrations page that names systems and limits, a support page that lists channels and response times, a pricing philosophy that explains inclusions and exclusions, and an industries page that ties outcomes to specific contexts. When those facts appear consistently across your site and a handful of trusted third‑party pages, the recommendation prompt starts working in your favor.
In other words, this is How to Rank on Gemini's Answers when a buyer asks for a shortlist
2. Job‑to‑be‑done request
It is where net‑new demand often emerges. Buyers describe the outcome they want: reduce cloud spend, speed up security reviews, compress implementation timelines, increase lead‑to‑SQL conversion and ask which platforms will get them there.
These questions rarely name categories, which is why traditional keyword tools do not capture them.
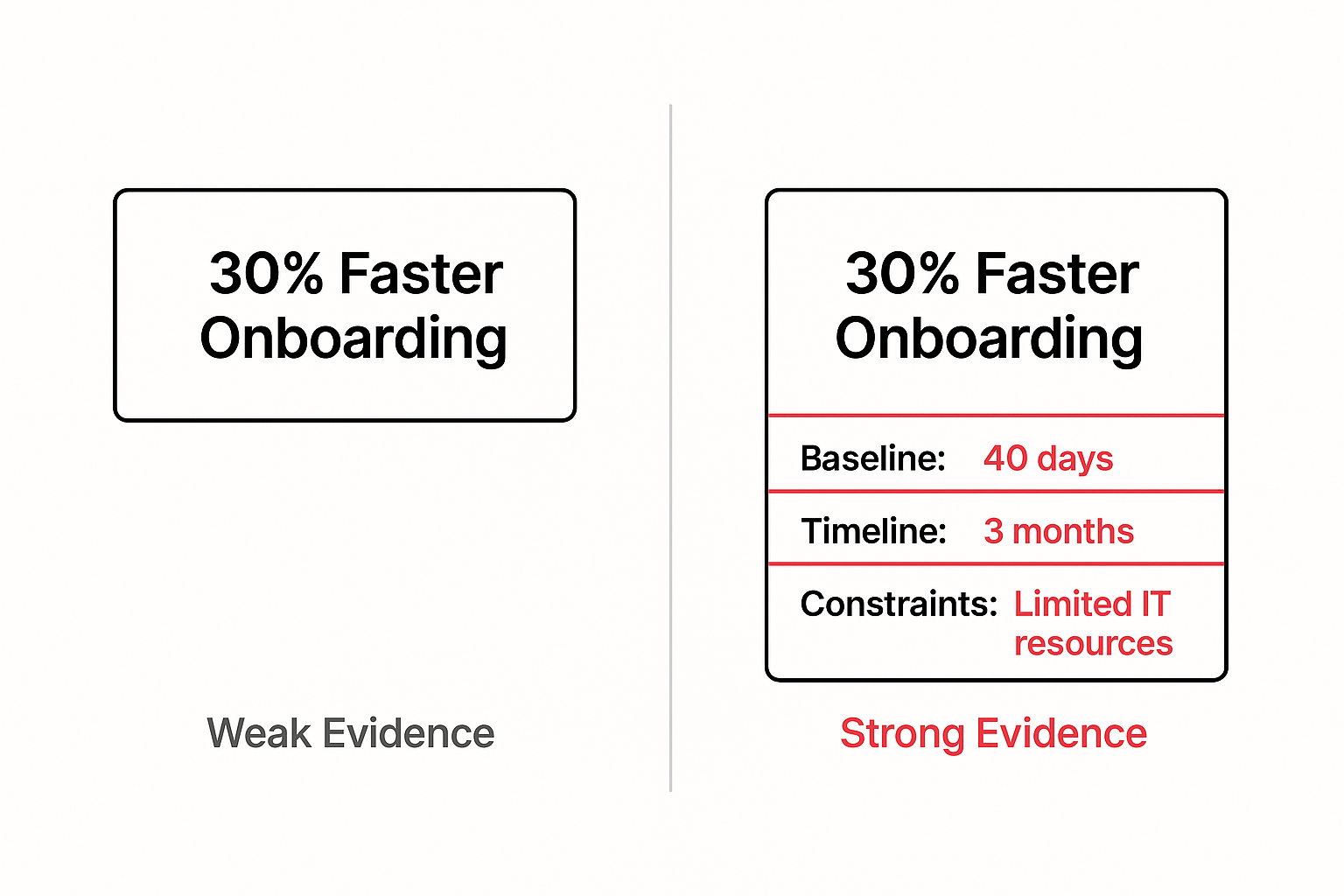
Gemini, however, looks for evidence that your product reliably delivers the result described. To be considered, you need pages that anchor your product to outcomes with numbers, time frames, and preconditions. A case study that reports a percentage improvement without context is weak evidence; a short narrative that explains the baseline, the levers used, the time to first value, and any constraints the customer had to meet is strong.
The same applies to playbooks and solution pages: when you explain how the outcome is achieved and where it does not apply, the model can lift those sentences to justify placing you in the answer. Over time, outcome‑specific pages become magnets for JTBD prompts because they read like the answer Gemini wanted to give.
3. Comparison
When a buyer asks whether A is better than B for a particular scenario, Gemini favors sources that present structured, candid explanations.
It is looking for which features exist and how they behave under real constraints, what pricing actually includes and excludes, what the integration really supports versus what the logo implies, and how support operates on ordinary days and during incidents.
Pages that acknowledge trade‑offs and name the conditions under which a competitor is the better choice tend to be reused because they sound like advice instead of sales copy. If you can describe, in plain paragraphs, why you are the safer implementation for a mid‑market team with a small admin staff, or why your onboarding takes fewer calendar days for a specific stack, Gemini can cite those lines directly.
The key is to make the comparison page a reliable reference rather than a rebuttal; when it reads neutrally and still reveals your advantage, the model and the buyer both trust it.
4. Brand validation
Buyers ask what you do, who you serve, how you price, whether you comply with the standards that matter to them, and how support is delivered when something breaks. If your answers drift across your site, your review profiles, and your PR, Gemini will fill the gaps with guesses or with the first version it finds, which may be outdated. If the same crisp statements appear everywhere, the model will repeat them and move on.
The defensive move here is straightforward: keep canonical statements current and easy to quote. An About page that states headquarters and regions served, a Compliance page with certifications and dates, a Support page with channels and response targets, and a succinct overview of pricing structure give Gemini the anchors it needs.
When those anchors are corroborated by third‑party mentions: review platforms, listicles, and a few credible trade articles the brand prompt ceases to be a risk and becomes one more place your narrative is reinforced.
A Simple Framework That Keeps You Out of the Weeds
A practical program for Gemini doesn’t start with tools; it starts with clear inputs and disciplined logging. The framework is intentionally simple so it survives contact with busy calendars and shifting priorities.
You identify the prompts that matter, you discover which sources shape the answers, and you publish credible proofs that make you the logical choice. But If your goal is how to rank your website in gemini answers, this three-step loop is the shortest path.
1. Identify the prompts that matter
This means testing the questions a qualified buyer would actually ask.
- Sit with sales and customer success to collect the exact wording buyers use at the decision stage.
- Recreate those prompts in Gemini with realistic constraints such as company size, industry, region, budget range, existing stack, and regulatory requirements.
- Capture the full text of each prompt rather than a summary so you can rerun it verbatim later. Record which vendors appear, how they are positioned, and which criteria seem to explain inclusion or exclusion.
- If Gemini repeatedly highlights “transparent pricing” or “SOC 2 with data residency options,” note that explicitly.
- Keep a single living document usually a spreadsheet with columns for prompt text, context, cited vendors, cited sources, extracted criteria, and observations so your team can see demand patterns instead of debating hypothetical keywords.
Over a week or two, the set should stabilize into a usable map of bottom‑of‑funnel demand that everyone can reference.
2. Reverse‑engineer the sources behind those answers
When Gemini shows citations, open them and read the exact passages that are being used. When it does not, trace distinctive phrases or statistics from the answer back to likely pages using quoted searches and site‑restricted queries.
- Note the type of page you find: review profile, listicle, PR article, product documentation, support policy, YouTube transcript and the claim it seems to support.
- Track frequency, recency, and specificity so you can distinguish between a domain that appears everywhere and a paragraph that actually carries the decisive fact. Patterns emerge quickly.
- In some categories, a single niche review site is referenced far more than household‑name platforms. In others, two or three “Best of” articles quietly drive most shortlists. In emerging spaces, Medium posts and LinkedIn Pulse essays punch above their weight because their structure makes facts easy to reuse.
- Turn these observations into a source map that lists each URL, the claim it anchors, the prompts it influences, and whether you are already included, missing, or misrepresented.
This map becomes your hit list for outreach and content upgrades.
3. Publish credible, quotable proofs so that Gemini can recommend you without improvisation.
Translate the criteria you keep seeing: support responsiveness, onboarding time, integration coverage, compliance scope, pricing inclusions into pages that state facts cleanly and consistently.
- Write in short, specific sentences that a model can lift without editing.
- Place definitions near first mention so context is never ambiguous.
- Acknowledge limits and explain workarounds; a candid sentence that names a constraint is more reusable than a vague superlative.
- If hard pricing numbers are not publishable, write a pricing philosophy that explains the model, what is included, what is billed as usage, and when a plan is not a fit. Give each major integration its own page with capabilities, limitations, and setup steps.
- For industries you serve, anchor claims with concrete outcomes and the stack conditions under which those outcomes were achieved. Treat these pages as canonical and keep them in plain HTML, not tucked behind scripts or PDFs.
- Mirror the same facts, in the same words, on the third‑party surfaces your source map identified so the model encounters consistent language in multiple credible places.
When you do this well, answers stop sounding like generalizations and start repeating your sentences back to you.
The Five Website Dimensions That Matter for Gemini
If you’re looking for a practical view on how to rank in google gemini, treat these five dimensions as the foundation. They are less about tricks and more about making your strongest claims easy for a model to discover, verify, and reuse across contexts.
1) Technical foundation
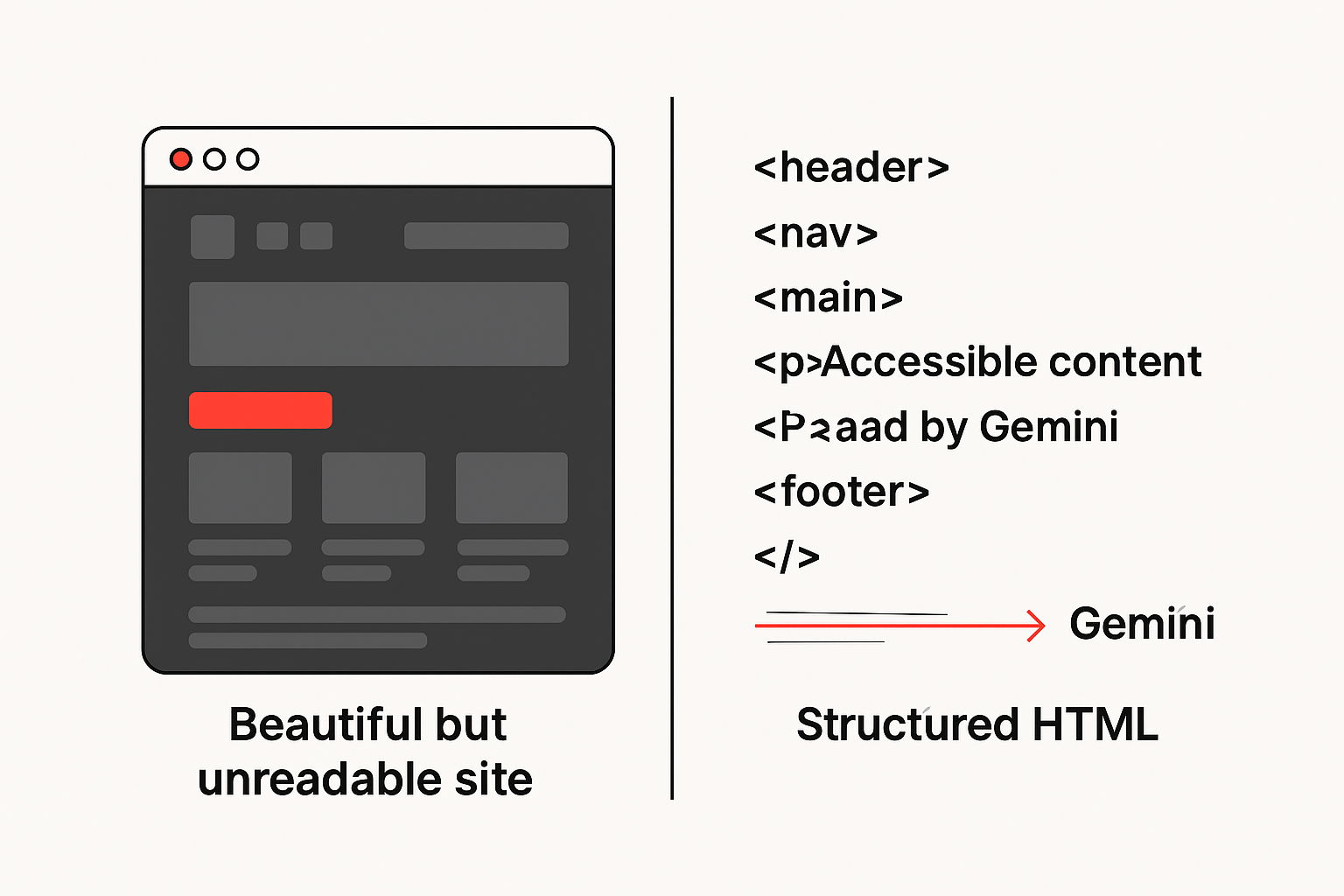
The first time we “optimized” our site, it looked beautiful, but ChatGPT barely saw it because we shipped as a heavy JavaScript app. Models and crawlers fare better with server‑side rendered HTML and accessible markup.
If your strongest pages hide behind client‑side rendering, the model may never read them. Treat speed and accessibility as prerequisites, not afterthoughts. Remove thin and duplicate pages that cannibalize meaning. Keep key facts in text, not in images or PDFs that lack full text equivalents. Think of the site as a source of structured truth rather than a brochure with moving parts.
2) Content strategy anchored to bottom‑of‑funnel criteria
LLMs respond to decision‑stage questions by checking for decision‑stage facts. Map the criteria that show up in your sales calls and in Gemini’s answers: support responsiveness, SLA scope, onboarding requirements, integration depth, compliance frameworks, data residency, pricing rationale and give each one a permanent home on your site.
When we realized ChatGPT was discounting our support because we didn’t surface it, we published a public support page that described channels, response targets, and escalation in plain language. Visibility followed because the model finally had something specific to quote.
3) Conversion ecosystem that spans every surface
The distinction between SEO pages and paid landing pages exists in your analytics, not in Gemini’s world. The model will borrow from any public surface it can find.
If your best explanation of packaging lives only on an unindexed landing page, it will not be considered. If your claim appears with three different wordings across your site, your reviews, and your PR, the model will pick whichever wording it encountered first. Pull the best language from ads, sales notes, and success stories into the primary site so that there is one canonical statement for every critical fact.
4) Narrative and messaging consistency
Language that is clear, confident, operational, empathetic, and free of fluff travels farther. Clear language drops buzzwords and says what a buyer would repeat on a call. Confident language owns a claim and stands behind it with a reason. Operational language shows how, not just what.
Empathetic language respects context and constraints. No‑fluff language replaces vague promises with timelines, percentages, and outcomes. Once you decide how to describe your product and your proof, describe it that way everywhere so the model never has to reconcile contradictions.
5) Presence beyond your domain
Gemini often grounds answers in third‑party pages because they act as independent corroboration. Review platforms, listicles, trade publications, and YouTube transcripts are frequent sources. Start by auditing which of these surfaces appear in your prompts. Then make deliberate moves. Choose the review platform that actually shows up in your niche rather than the one with the biggest brand name. Ask customers to mention the specifics you want to win on, such as onboarding time or the systems you integrate with.
Reach out to authors of the listicles that reappear and supply a small, fact‑checked paragraph that is easy to paste and easy to cite. When you run PR, target outlets the model already trusts and angle stories toward the criteria you want to anchor.
Deep Execution
1. How to build a prompt set that doesn’t waste time
Start by collecting verbatim questions from real deals rather than inventing hypotheticals.
- Sit with two account executives and a CSM and ask for the last ten moments when a buyer hesitated or asked for a recommendation.
- Write those prompts exactly as the buyer said them, including qualifiers like headcount, regions, stack, compliance, and budget ceilings.
- Recreate each one in Gemini with the same level of detail and record the full prompt text so you can rerun it later without drift. For every run, capture who appears, how they are described, which facts were referenced, and what criteria seem to explain inclusion.
- Resist the urge to compress or paraphrase; fidelity matters because small phrasing changes can produce different answers.
- After the first pass, look for missing perspectives: security, finance, operationsand add prompts that represent those functions so the set reflects the buying committee rather than a single persona.
- Within two or three working sessions, you will have twenty to fifty prompts that mirror decision‑stage demand.
- Put them in a single sheet with columns for prompt text, context, vendors mentioned, order of mention, sources, extracted criteria, and observations.
This becomes your baseline for all future testing and a shared artifact that stops debates about keywords and keeps the team focused on moments that create or remove you from a shortlist.
2. How to map sources without getting lost
Treat source discovery like a small research sprint with a consistent routine.
- For each prompt, open the citations if Gemini shows them and read the passages it used; paste the quoted lines into your sheet so you can see exactly what language is driving the answer.
- When citations are not visible, search for distinctive sentences or statistics from the answer in quotes, then widen to site‑restricted queries on domains that commonly publish in your category.
- Record the URL, the page type (review profile, listicle, PR article, documentation, support policy, YouTube transcript), the specific claim it contributed, and the date last updated.
- After ten to fifteen prompts, sort by URL frequency to reveal clusters.
- If a single “Best of” article appears in half of your relevant answers, it is high‑leverage and deserves targeted outreach. If a niche review site shows up repeatedly with detailed quotes about support or onboarding, that is where you should build and curate reviews first.
- Note recency alongside frequency; a page updated last month with crisp, structured claims often carries more weight than an older, vague one.
- Add a simple confidence column to capture how certain you are about a page’s influence so you can revisit ambiguous items later.
The output of this sprint is a compact source map that lists the pages most likely to shift recommendations, the specific assertions they anchor, and whether you are included, missing, or misrepresented on each.
3. How to write pages the model loves to reuse
Write like a product marketer who must be quoted accurately in someone else’s slide deck.
- Lead with a single sentence that states the gist in terms a buyer could repeat without you in the room.
- Follow immediately with specifics that anchor that gist in reality: numbers, time frames, integrations, scope, and limits.
- Keep definitions near the first mention so context is unambiguous.
- Where there is a constraint, say it plainly and describe the workaround rather than leaving room for inference.
- Name the segment you are best for and explain why, using factors like team size, region, stack, or compliance posture.
- Address the predictable objection a skeptic would raise in the next paragraph so the page reads like responsible guidance rather than advocacy.
- When explaining pricing without publishing numbers, spell out inclusions, usage‑based elements, and the scenarios where a given tier is not a good fit.
- For integrations, describe capabilities and limitations in concrete terms, and outline setup steps so the model can recognize implementation shape.
- For industry pages, tie outcomes to starting conditions and tools already in the stack so results feel replicable instead of aspirational.
- Keep the prose compact and declarative; short, specific sentences are easier to quote correctly.
- Where a table would clarify, use one, but ensure the surrounding paragraphs carry the same facts so the evidence survives outside the table.
Publish in server‑rendered HTML, not behind heavy client‑side rendering or in PDFs without full text, and give each page a stable URL so future citations do not break.
4. How to distribute facts beyond your site without spamming
Use your source map to pick three high‑impact surfaces for the month and concentrate effort there.
- When you approach a listicle author, send a concise paragraph written in the page’s style that includes one quotable claim, a link to the canonical page on your site, and a recent example or metric that proves the point.
- Offer to provide a corrected definition, a fresh screenshot, or a short clarification table that improves the article for readers; the goal is to be useful, not noisy.
- For review platforms that appear in answers, run a focused ask to power users and recent champions, guiding them: without scripting to mention onboarding time, support responsiveness, and the systems they integrated, because those details are the ones Gemini tends to lift.
- If PR pages are influential in your space, pitch angles that anchor criteria you want to win, such as a new support program with response targets or a deeper native integration with a system your segment depends on.
- Link the press piece back to your canonical proof page so there is a loop of reinforcement.
- Republish a small number of your highest‑value pages on Medium or LinkedIn Pulse with canonical links or clear attribution so redundancy works in your favor without creating confusion.
- Track each placement with a simple note in your sheet: the URL, the claim added, the date live then rerun the prompt set to verify movement.
- A single paragraph placed on a page that appears in dozens of answers will outperform a scattershot campaign across low‑leverage surfaces, so bias toward depth over breadth and measure by changes in citations and recommendations rather than vanity metrics.
In practice, this is how to get featured in gemini consistently,
Misrepresentation Management as an Ongoing Workflow
1. Why errors stick around and how to dislodge them
Large language models don’t wake up and decide to mislead people; they generalize from what they can find and what they have internalized. When a decade‑old pricing blog post lingers on your domain with obsolete terms, it is still a perfectly valid input unless something newer and clearer supersedes it. When a review implies you only serve enterprise while your best customers are mid‑market, that implication can cascade because the model sees no equally strong, recent counterweight.
Even subtle inconsistencies: different wording for the same feature across your site, a support promise phrased three ways in three places invite the model to pick one version and repeat it.
The remedy is to treat every wrong claim like a ticket with an owner, a severity, and a fix. If the source is your page, update it in place with precise, dated language and keep the URL stable so future crawls discover the correction.
If you must retire a page, replace it with a short explainer that redirects readers to the updated source rather than a dead end, and avoid leaving unhelpful copies on subdomains or in PDFs that continue to surface. If the source is a third party, request an edit in professional, specific terms and include the exact sentence you’d like them to use along with a link to your canonical page.
When there is no visible source at all, publish an anchor page that states the fact unambiguously headquarters, compliance, pricing philosophy, support SLOs and reference that page whenever you can so the model has a clean target to cite. Over time, repetition of the correct phrasing across credible surfaces does the heavy lifting; you are re‑weighting the model’s priors with orderly evidence.
2. How to monitor without boiling the ocean
You do not need a war room to keep misrepresentations in check; you need a cadence you stick to. Pick one week each month to re‑run your prompt set and review the resulting answers with fresh eyes. Scan for drift: facts that used to be correct but have gone stale, new phrasing that suggests the model found a different source, or recommendations that now exclude you after a competitor shipped a visible proof page. Skim the sources that appear and decide whether to engage.
Maintain a compact log that records the misstatement, the likely source, the action taken, and what happened on the next run.
Annotate each entry with severity: critical for pricing, compliance, or ICP errors; high for support or integration scope; medium for positioning quirks; low for benign wording differences so you can prioritize in a calm, repeatable way. If you sell in multiple regions, include one or two region‑specific prompts so you can spot localized errors early, such as data residency claims that only apply in one market.
This lightweight process is enough to surface problems before they affect a quarter’s pipeline and to prove, to yourself and to stakeholders, that the narrative is stabilizing.
3. Leading indicators you can trust
Because there is no single “rank” to screenshot, you need proxies that correlate with revenue rather than vanity. Citation share is the first: in what proportion of your target prompts do your pages or your third‑party mentions appear as sources.
Track it by counting distinct prompts where at least one of your canonical URLs or targeted external pages is surfaced, divided by the number of prompts in your set.
Recommendation share is the second: how often the answer frames you as a strong option for a scenario you care about or elevates you as the default choice. Define the denominator clearly: total prompts where vendors are recommended and score conservatively to avoid false confidence. Misrepresentation count is the third: the number of materially wrong claims per hundred prompts, trended over time.
When citation and recommendation shares rise while misrepresentations fall, you will hear the change in sales calls: prospects arrive with fewer basic objections, and discovery focuses on fit rather than fact‑checking. If you’re wondering, ‘How to optimize for Gemini AI?’ these are the levers, and they are also the levers behind how to rank on gemini answers.
4. Lagging indicators that close the loop
Attribution has to be believable or it will be ignored. Use a consistent UTM convention for links you control source set to “gemini” or “ai‑overview” where appropriate, medium “answer‑engine,” and a campaign name that maps to the prompt theme so GA4 and your warehouse can distinguish traffic you expect from organic spillover.
Mirror those conventions in your CRM by adding a simple channel field and a short list of values rather than inventing a new taxonomy.
Correlate answer‑engine sessions and demo requests to opportunity creation, and track cycle length and win rate for those cohorts. When prospects mention seeing your comparison table or support policy inside an AI answer, capture that verbatim in a field on the opportunity or in call notes so you can review qualitative signals alongside quantitative ones. The goal is not to build a perfect model; it is to close the loop enough that you can re‑invest with confidence.
5. Who should own what across the team
Clear ownership prevents thrash. Product marketing owns the narrative and the proof pages: support, pricing philosophy, integrations, industries, and comparisons because they sit closest to positioning and buyer truth.
- SEO owns crawlability and the research discipline that keeps the prompt set and source map accurate and current.
- Content owns drafting, editing, and republishing on external platforms so the same facts travel cleanly across surfaces.
- PR owns outreach to outlets the model already trusts and ensures that press pieces reinforce the exact phrases you want repeated.
- Sales and success own the reality check: the criteria buyers actually use to choose, the objections that derail deals, and the phrasing prospects bring to calls.
When these functions work from the same prompt set, the same source map, and the same style guidance, execution accelerates and contradictions evaporate.
6. What a healthy monthly rhythm looks like
A sustainable cadence beats one‑off heroics.
- In week one, re‑run the prompt set, refresh the source map, and identify any drift or new opportunities.
- In week two, publish or update one or two high‑impact pages often a comparison, an integration, or a support policy you now understand better after the review.
- In week three, distribute: place updated facts on the third‑party surfaces that showed up in your audit, from listicles to review profiles to targeted press.
- In week four, review results, triage misrepresentations, and plan the next sprint.
This rhythm works for small teams because it compresses the work into predictable blocks, and it scales for larger teams because each function knows its window to contribute.
7. Why regional details and certifications matter more than you think
Regional accuracy is a common source of silent exclusion. If you sell in multiple markets, state data residency options, supported languages, currencies, and tax considerations plainly, and keep those statements time‑stamped so a model can favor the newest version.
If your compliance posture changes: SOC 2, ISO 27001, HIPAA, GDPR commitments publish the change with scope and date and link it from places models already read, such as your footer and your About or Compliance pages.
The same applies to analyst coverage, awards, and partnerships: contextualize why they matter instead of listing logos without explanation. Trust signals are most useful when they answer a question a buyer would actually ask and when they are expressed in sentences the model can reuse without interpretation.
What changed when we applied this to ourselves
When we applied this approach to our own site, we began by running the real prompts we were hearing from buyers and logging where we were absent or misrepresented. We traced answers back to a concentrated set of third‑party pages and a short list of missing proofs on our domain.
We then published a public support page that spelled out channels, regions, and response targets in plain language, a pricing philosophy page that described inclusions and exclusions without hand‑waving, and integration and industry pages that showed capability and fit with specific examples. In parallel, we contacted authors of a few high‑impact listicles to provide updated, fact‑checked blurbs and refreshed screenshots, and we encouraged recent champions to leave reviews that mentioned onboarding time and stack fit.
Within weeks, we saw our pages appear as sources and our brand mentioned in scenarios that had previously defaulted to competitors.
The change felt linear rather than dramatic because it was the predictable result of placing the right facts in the right places and removing stale versions that confused the narrative.
Conclusion: Turning Visibility into an Enduring Advantage
Throughout this guide, we’ve explored what effective gemini SEO looks like in practice: how to build evidence, structure facts, and optimize content for better visibility in gemini generated answers. Along the way, we’ve discussed the role of gemini tracking, how to interpret patterns from gemini refer data, and why gemini SEO now functions as a distinct layer of modern search strategy.
The mechanics of how to rank on Gemini are not mysterious once you strip away the jargon. Gemini rewards clarity, evidence, and consistency. It does not need gimmicks; it needs facts that a buyer can trust and a model can quote. When you make those facts easy to find: on your site, in reviews, and across the publications the model already reads you move from being discoverable to being defensible. Each correctly worded paragraph, each refreshed citation, and each cleanly rendered proof page compounds over time, creating a network of corroboration that LLMs rely on. The teams that win here are not louder; they are more deliberate.
In 2026 and beyond, the brands that understand how to rank on gemini answers and how to get featured in gemini will be the ones that treat AI search as a living ecosystem rather than a campaign. Keep publishing verifiable information, maintain the same phrasing across your digital surfaces, and update it before the model does it for you. The return will show up not just in visibility metrics but in shorter sales cycles, stronger trust in discovery, and a reputation that sustains itself in every AI‑driven recommendation. That is the quiet, compounding power of true AI Search Optimization.
FAQs
1. Does SEO for ChatGPT replace traditional SEO?
No. SEO hygiene creates the foundation that lets models find and parse your claims: crawlability, speed, structured data, and a logical site architecture. AISO adds the layer that turns visibility into recommendations by supplying decision‑grade facts and third‑party corroboration the model can cite. Teams that pair both see more stable results.
2. How do I know what Gemini believes about my brand?
Run an audit using your real buying prompts, not abstract keywords. Capture mentions, recommendations, and sources, and compare them to the criteria you believe should determine fit. If you prefer not to hand‑roll it, use a platform that automates prompt runs and source mapping. Either way, close gaps with public pages and credible citations you control.
3. Do I need to rebuild my stack to get this right?
Rarely. You need server‑rendered, accessible pages that state your strongest claims in text and remain stable at known URLs, and you need those claims to be consistent wherever they appear. Start by fixing rendering and content clarity; add sophistication later if you need it.
4. How quickly do results show up?
LLM answers tend to refresh faster than classic search rankings. If you publish a few high‑impact proof pages and secure a handful of credible third‑party statements, you can observe movement within weeks. The exact timing depends on crawl frequency in your category and the freshness of the sources you influence.
5. What is the fastest way for a SaaS brand to improve LLM visibility?
Pick one comparison scenario you frequently encounter, one high‑value integration your customers rely on, and one industry where you already win. Publish clear, quotable pages for each on your site, then place the same facts on one review platform and one listicle that appear in your category’s answers. Re‑run your prompt set, confirm movement in citations and recommendations, and iterate with the next scenario.