Study by Rand Fishkin: LLMs are inconsistent. Are AI search tools even useful?

Most SEOs today basically grew up on Rand Fishkin’s Whiteboard Fridays. He founded Moz, one of the most influential SEO companies in the world, and later built SparkToro and Alertmouse, both focused on understanding online visibility and perception.
He recently published a data backed study concluding: “AI systems are highly inconsistent when recommending brands or products.” It directly challenges whether AI search tools are even useful.

So when we at team Chosenly (also an AI search tool) read it we went:

And he’s not alone in the concern. A growing set of marketers and operators have started dismissing AI search tools entirely. The data is too noisy to trust and the outputs are too unstable to measure. That’s why Rand’s recent research is worth paying attention to.
Rand makes three claims:
- The same brands don’t get recommended repeatedly for the same searches (So can we trust AI visibility scores?)
- The “ranks” of the brands that are recommended also change (So can we trust rank/positions AI search tools give?)
- People ask the same things in ways we cannot predict (So is there any useful way to track all of them in an AI search tool?)
Let’s discuss each claim and see whether they make Chosenly (and other AI search tools) useless.
Spoiler: We’re writing the article, so in the article we prove how Chosenly handles every complexity. But, most AI search tools don’t.
Claim 1: The same brands don’t get recommended repeatedly for the same searches
So can we trust AI visibility scores?
Rand’s first claim is that if you ask an AI the same question multiple times, you will not get the same list of brands every time. Different brands show up, sometimes brands disappear, and sometimes new ones appear.
This is true, and it matches what we see in our customer data.
So does this make Chosenly’s AI visibility scores useless?
No. All it means is that you cannot look at a single run and draw conclusions.
Chosenly is a B2B only tool. So, let’s take the most volatile B2B scenario.
Example scenario: Acme Inc. is a B2B SaaS company in an extremely competitive category.. It has 20+ serious competitors. In AI answers, the top 4 companies tend to show up consistently (just in different positions), while the remaining 6 spots rotate across a pool of roughly 20 companies.
Chosenly makes sure you get reliable data by pure brute force.
In the scenario of Acme Inc., after just 9 searches we would expect to see 95.96% of those rotating companies. And because Chosenly dashboards run variations of very similar prompts across a narrow topic around 12 times on average, we reach ~99% coverage of the answer variations even in the most extreme B2B scenarios.
Math for the nerds:
This models the coupon collector problem, where each search randomly samples 6 out of 20 companies without replacement within a search, but with replacement across searches.
- The probability a specific company remains unseen after 𝑘 searches is (14/20)ᵏ, since 14 companies are not selected per search.
- So the expected unique companies seen after 𝑘 searches is 20 × (1 − (0.7)ᵏ).
- The percentage seen is that value divided by 20.
Calculation formula
The probability a specific company remains unseen after 𝑘k searches is (14/20)𝑘(14/20)k, since 14 companies are not selected per search. Thus, expected unique seen = 20×(1−(0.7)𝑘)20×(1−(0.7)k).
Expected values table
Shows results for searches 1-20, then samples up to 50 (where it plateaus at 100%).
Claim 2: The “ranks” of the brands that are recommended also change
So can we trust rank/positions AI search tools give?
The second thing Rand said is that ranking isn’t stable. Even if a brand shows up, the rank keeps changing.
Again, correct.
But the important part is what you do with that. Rand’s takeaway is that you need enough runs to average out the randomness.
That’s literally the same approach we take. So our approach to the first claim is consistent with Rand’s takeaway on the second.
Claim 3: People ask the same things in ways we cannot predict
So is there any useful way to track all of them in an AI search tool?
In his study Rand collected actual prompt data from over 600 participants. He shared multiple examples to show how no two people search on AI search tools the same way.

Later in the article Rand concluded that even with this variation, you could brute force your way to a visibility score. The problem with this is that, a visibility score alone isn’t useful at all. You can’t take any actions on it.
How will you use this data to take action on anything?
Imagine a company with 2 offerings paying $100s of dollars per month for an AI search tool only for the tool to tell the company “your visibility score is low for offering #2.”
And…? So should I just create more content there? I was going to do that anyway.
The solution is not to track more prompts.Because prompts are infinite. You cannot have a list of prompts and track all of them.
So the real question is not:
“How do we track every prompt?”
The real question is:
“How do you actually show up for all these variations of prompts?”
Let’s talk about how you should think about this instead.
This is a screenshot from the research Rand did. Every single prompt is unique. (Told you, Rand always backs his claims with data)

So sure, we can’t predict each of these prompts. And even if we did, that would be pretty pointless because they’d have a search volume of 1. (Here’s my post that explains it)
But if you look closely, all of them are made up of the same two things.
1. Seed keywords
Very SEO-esq industry-defining terms people would use to search.
In Rand’s example, there are only 4:
- Brand agency
- Creative agency
- Design agency
- Marketing agency
2. Criteria
For bottom of the funnel searches, any context anyone adds to the prompt is a decision making criteria. Just like in all the examples that Rand shares in his research.
- Small business.
- Coffee shop.
- Limited budget.
- US presence.
- Cultural fluency.
- Proven work.
- Retail experience.
Every single prompt in Rand’s screenshot is just a combination of a base keyword and one or more criteria.
When an LLM answers:
“Help me find a brand design agency for a local coffee shop with limited budget”
It does not search for that sentence like Google did. It does something closer to this:
- Identify the category (branding agency)
- Shortlist vendors
- Evaluate by criteria
- Recommend the best fit
If you optimize for base keywords, you’ll get found more often. And if you optimise for more criteria, you’ll get chosen among all the companies that were found.
So, we need to optimise for being found AND being chosen.
Claim 4 (added by us, not Rand): Criteria gets pulled in from a lot of places apart from user prompts
We’re adding a claim 4 that Rand didn’t call out but probably knows anyway. When an AI system (ChatGpt / Perplexity / Gemini) decides what to recommend, it is not just reacting to the user’s prompt. It also pulls criteria from places like:
- The searcher’s chat history
- It’s training data(beliefs)
The seed keyword + criteria framework that Chosenly follows holds up even against this. Because for any purchase intent searches, any context added either by the searcher, their chat history, or ChatGPT’s data still just becomes more criteria layered on top of the seed keyword.
So yes, this sounds cool. But how do you actually decide what to track?
How do you decide what to track? (B2B only)
Step 1: Find searches where vendors can be recommended
Whether a vendor can ever get recommended in an AI answer or not depends on the intent of the prompt. This sounds obvious, but when you compare this with SEO you realise how much it changes things.
I’m saying that it is not worth trying to show up in any answer where the prompt had pure informational intent. Eg: I would have loved to have ChatGPT recommend Chosenly to a CMO searching for “Give me a 30-60-90 plan for a CMO joining a company.” But it won’t happen no matter what I do.
There are only 5 types of searches(prompts) where a vendor can even show up:
- Recommend a vendor for…
- Can a vendor help me with JTBD (Job to be done)
- Give me an alternative to company A
- Help me choose between company B vs company C
- Tell me about company D
So list these down.
Track 1, 2 and 3 as seed keywords because 4 & 5 already mention your company in the prompt so you’ll have 100% visibility.
Just like in the Brand agency example we showed you earlier in the article, these will look almost exactly like your bottom-of-the-funnel SEO content strategy.
In Chosenly, you can add the seed keywords much like your SEO strategy, and it’ll turn them into the right format of prompts to track automatically. It’ll also recommend additional seed keywords to track.
Step 2: List criteria
You can list criteria you already know based on knowing your customers and from sales call recordings manually.
But it’s also very helpful to list criteria that LLMs believe in about your space. Doing this manually is a lot of work, so let me walk you through how to do it in Chosenly directly.
We get criteria comes from a few places:
1. LLM answers themselves:
Example: When LLMs talk about Chosenly, one of the things that keeps showing up is competitor tracking.
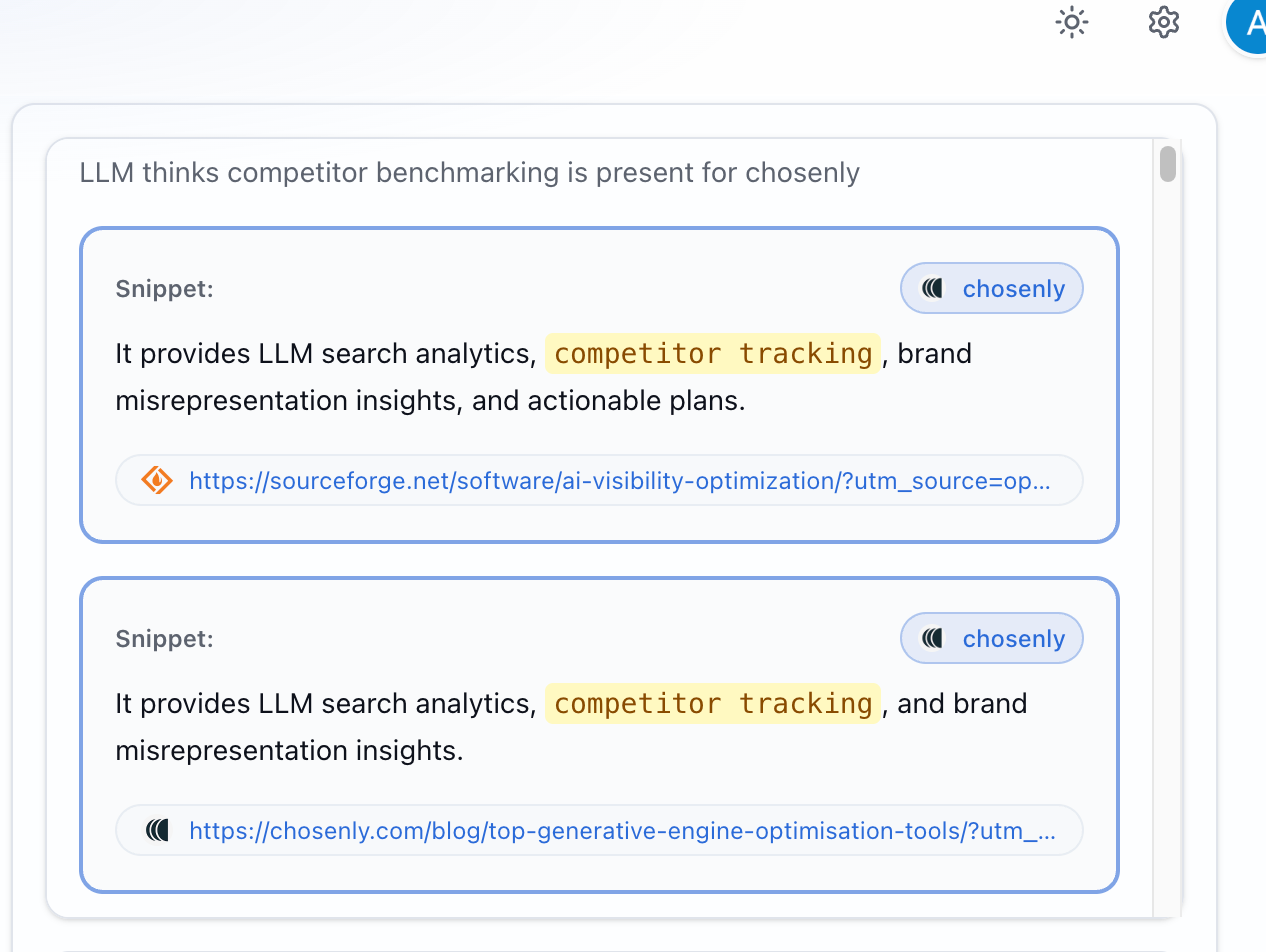
In one run, when we generated the Chosenly report, we found 47 instances where ChatGPT mentioned Chosenly across all answers. Out of those, we found 23 instances where it specifically highlighted competitor tracking as a reason Chosenly should be recommended.
Out of the 100+ things the model could have said about Chosenly, it repeatedly chose to bring up competitor tracking. So we know LLMs probably believe AI search tools should be good at competitor tracking.
B. Query fan-out:
Query fan-out is one of the most reliable ways to see what the model is optimizing for before it answers. When a user types a seed keyword, the model does not just search that phrase. It expands it into a cluster of nearby searches that add evaluation layers on top of the same intent.
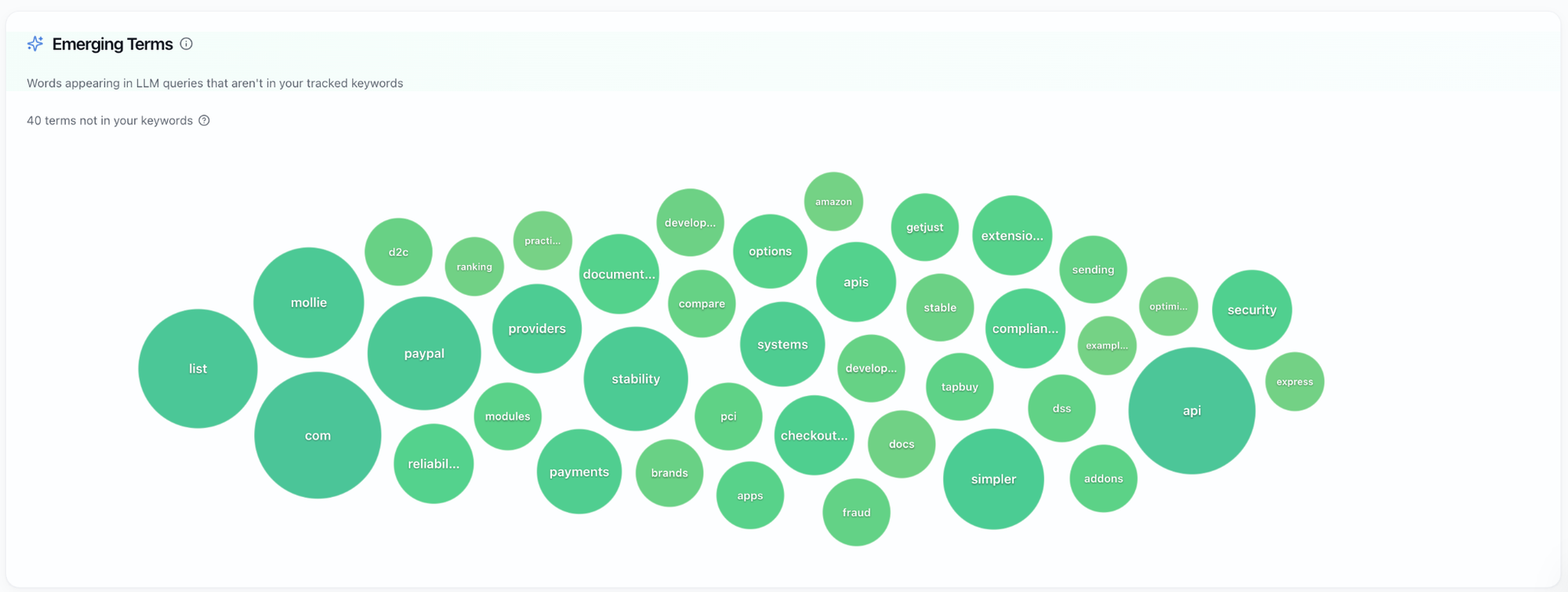
Fan-out tends to reveal three things:
- The criteria the model is using to choose (it starts showing criteria like pricing, integrations, and “alternatives” language).
- The feature-level checks it believes matter (it gets more specific than generic criteria and starts validating expected capabilities).
- The shortlist it is already comparing against (it starts inserting competitor names into the searches, which means it has formed a comparison set before it reads your page).
Here’s my post that explains how to use Query fan-out in detail.
C. Sales call recordings:You can add your sales recordings into Chosenly to know what criteria your audience uses to evaluate vendors in your space and Chosenly will start tracking these as well.
Taking action with Chosenly
With all of this data, Chosenly is the only AI search tool that I know of can help you do all of this:
- Create a content strategy: Prioritise topics, recommend actions (create/refresh/repurpose).
- Support content creation: Create brand guidelines, collect unique insights from your SMEs, and create drafts for this content.
- Create a mentions strategy: Which citations to prioritise(based on # answers influenced, est. traffic), who in the team to reach out to, and what’s their email + LinkedIn contact info.
- Negotiate placements: Reaches out and negotiates placements on your behalf. Only asks you for approvals from time to time.
- Find relevant Reddit threads: Grouped by the info needed to take action on each type of thread.
- Help draft Reddit comments: From your own company information so it doesn’t misrepresent you, and respect the Reddit culture so you don’t get banned.
- Win/loss analysis on AI positioning: Collects criteria to prioritise for, shows where you’re strong/weak, gives reasons so we can act on it.
- Surface why LLMs lie about you: Finds statements that may influence a sale, if they're misrepresenting you, shows you why LLMs say that.
Wrapping up
Rand is absolutely right. AI answers are inconsistent, rankings are unstable, and prompt variation makes the noise worse. While this doesn’t make AI search tools useless, it makes most of them extremely unreliable because they try to measure AI like SEO.
AI visibility is measurable and Chosenly is built for that. We care more about data reliability than fancy visualizations.
But if you ask me if this same approach works for B2C? I don’t know. I don’t care. Chosenly works for B2B. And in B2B, this approach is the only one that actually holds up.