How Chatgpt Works & Can ChatGPT Answers Even Be Influenced?


A year ago, the question everyone was asking about AI search was whether it was big enough to care about. Now the question has shifted. It’s whether there’s anything you can actually do about it.
If you’re reading this, you’re probably in camp two. You know AI search is happening. You’ve seen ChatGPT recommend companies. You’ve maybe even seen your own show up, or a competitor’s. And now you’re trying to figure out:
- how does chatgpt get its answers; and
- if you can actually influence what ChatGPT says;
or if this is a black box you just have to sit and wait out.
This article is for you. It’s written for the skeptical reader, as you should be. There’s a lot of hype in this space. A lot of money moving around. A lot of misinformation. Being skeptical is the right instinct.
We’ll focus on ChatGPT specifically, but most of what we say applies to the other major LLMs like Gemini, Claude, and Perplexity, too. They’ve all been built in broadly similar ways. What we’re trying to do is connect the inner workings of ChatGPT to the actions you can actually take to influence its answers. We’ve tried to simplify it where possible, but there’s a limit to how simple this can get without losing the point.
A heads-up before you go further: this isn’t an easy or fun read. It’s for people who want the specifics. How ChatGPT generates an answer. Which parts of that process you can actually influence, and which parts you can’t. If you just want something actionable, a checklist, a playbook, the quick version, you’re better off reading our GEO strategy guide instead. This article is for the why.
How does ChatGPT generate answers?
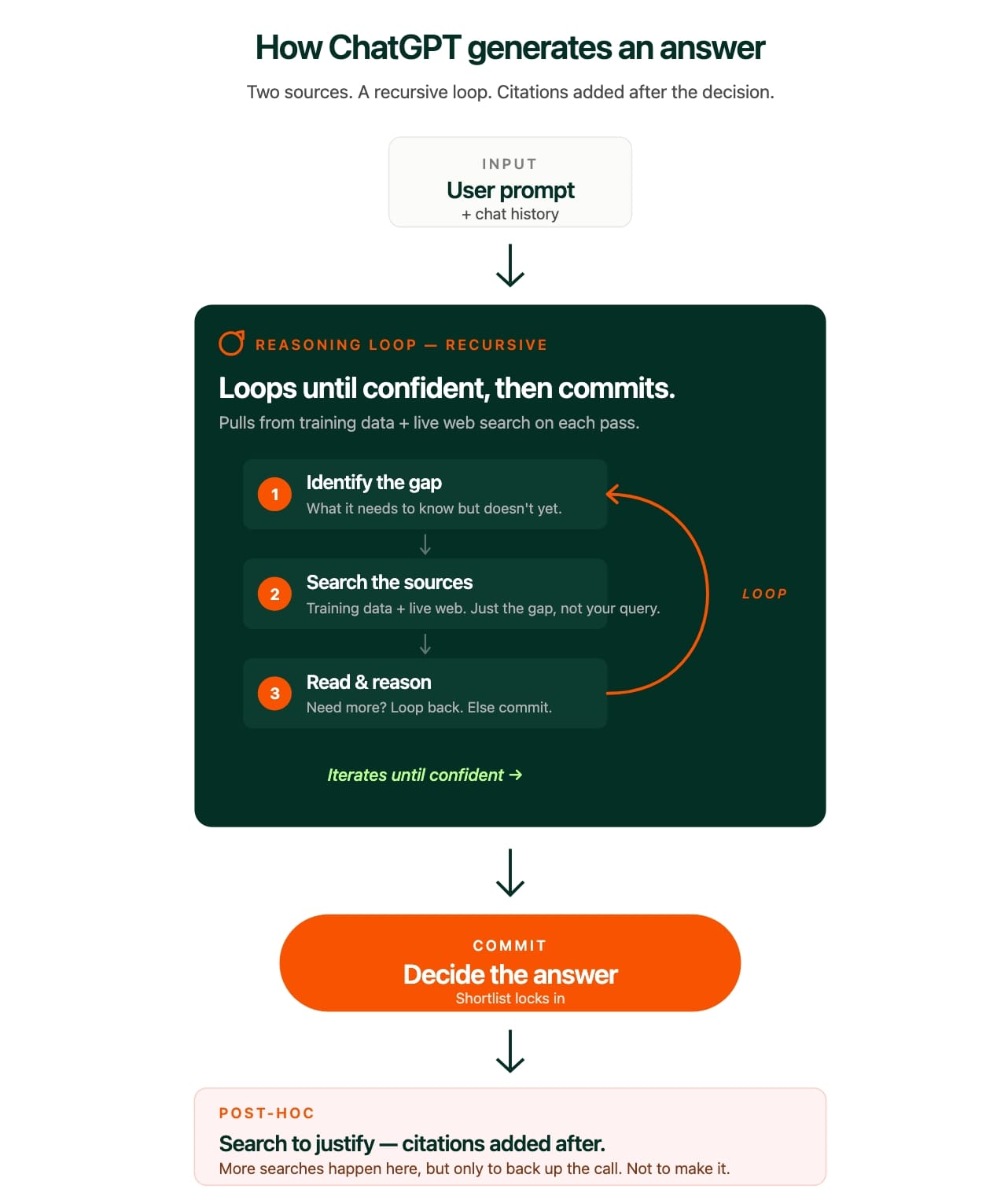
Here’s the uncomfortable truth: no one actually knows how ChatGPT works. Not fully. Not even the people who built it.
All we know is that if you take a model and feed it more and more data and more computing power, it starts doing things. Speaking. Reasoning. Writing. No one fully understood why it started doing these things. Only that the more data and compute you fed it, the more it could do. Every major lab today, Anthropic, Google, Meta, has entire teams whose full-time job is to figure out what’s happening inside their own models. They still haven’t fully cracked it.
But we’re not here to figure out why it works. We’re here because it clearly does work, and whatever it’s doing is already shaping what buyers see when they search for vendors. So what we care about is something more practical: can we understand enough about how it generates answers to reliably influence them? The answer is yes. The rest of this article is about exactly how much we know, and how much is enough.
When ChatGPT answers any question, its information comes from exactly two places:
- Its training data: everything the model learned when it was built.
- Live web search: pages it pulls in real time while generating an answer.
That’s it. Anything it says has to come from one of those two places. On top of that, it also uses the context you give it in the prompt, plus whatever it knows about you from your chat history. But those shape how it answers, not what information it has access to.
It doesn’t search the way Google does
This is the part that trips most SEO folks up. In Google, your query is the search. You type “best HR tool,” Google looks up “best HR tool” in its index, and shows what comes back. ChatGPT doesn’t work like that.
When you ask ChatGPT something, it first reads your prompt, looks at your chat history, and what it already knows from training. Then it figures out what it still needs in order to answer. Whatever it decides it needs becomes the search. Not your query. The gap between what it already knows and what it needs to know to answer you.
The same logic applies to whether it searches at all. If it’s confident it can answer from training data alone, it might skip web search entirely. For product recommendations, it almost always searches, because it knows its training data can be out of date and it wants recent information before it commits to recommending a company.
ChatGPT doesn’t do all its searches upfront, pull in all the information, and then generate an answer in one shot. It searches incrementally. It does a search. It reads what comes back. Based on that, it figures out what else it needs. It does more searches, reasons again, and at some point decides it has enough to generate an answer.
And once it’s decided the answer, it often does more searches after that, purely to justify the answer it already picked. To grab a citation. To back up a claim. To link to a source that supports what it’s already going to say. Think of an analyst who’s already made up their mind and is now building the slide to prove it. That’s ChatGPT in the final stretch.
You can watch this happen in the ChatGPT UI when web search is on. It shows you the searches it runs, in order, as it runs them. This isn’t a theory. It’s well-documented and you can see it live.
Once you accept that this is how the model operates, a set of useful questions falls out of it. Each one points to something you might be able to influence:
- What’s in ChatGPT’s training data?
- When does ChatGPT search, and when does it not?
- What does ChatGPT search for?
- How does ChatGPT read a page?
- Which citations actually matter, and which don’t?
The rest of this article works through these one at a time.
1. What’s in ChatGPT’s training data?
We can’t fully know what ChatGPT was trained on. That information lives inside the company that built it and we’ll never see it.
But we do know one thing for sure. A big part of the training data comes from the internet. Every time ChatGPT gets updated, it tells you its training data only goes up to a certain date. Between updates, more of the internet gets scraped and fed in.
Here’s why this matters. If something is on the internet, there’s a good chance it will end up in training data, if not in this update then the next. So the same content that gets cited in an answer today can also become part of the training data tomorrow. The line between “citations” and “training data” is much fuzzier than most people think.
Training data is also biased toward recent information for buying decisions. ChatGPT’s system prompt was reportedly reverse-engineered at some point, and it indicated that for buying decisions the model should fetch recent data. This makes sense. What was the best sales course in 2015 isn’t the same as what’s the best sales course today. So even when answering from training data alone, the model is leaning on the most recent training it has.
One more signal worth knowing about: you can sometimes see what the model already believes by looking at its query fanout. That’s covered in the next section.
2. When does ChatGPT search, and when does it not?
ChatGPT doesn’t search the web for every question. Sometimes it answers from training data alone. Sometimes it searches. What decides this?
It comes down to a confidence score. The model checks how confident it is that it can answer the question from what it already knows. If its confidence is high enough, it skips the search. If it’s not confident enough, it searches.
Two examples of high confidence:
- “Who wrote Harry Potter?” The model knows this with near certainty. It doesn’t need to search.
- “What trainers should I buy?” in an established market. The model thinks “Nike” and is so confident it might not even search. The belief is so strong it doesn’t feel the need to verify.
Two examples of low confidence:
- Niche or newer markets, where the model is less sure who the best player is.
- Anything recent, like “what’s the best AI search tool this year?” The model knows its training data might be out of date, so it searches.
There’s also a rule that overrides the confidence score. When the question asks for current or recent information, it searches anyway, even if confidence is high. Product recommendations almost always trigger this. ChatGPT’s system prompt reportedly says that for buying decisions, it should fetch recent data. So for most product recommendation queries, it searches by default.
3. What does ChatGPT search for?
When you ask ChatGPT something, it doesn’t just searches the way Google does. It first looks at your prompt, your chat history, and what it already knows from training. Then it figures out what it still needs to answer you. Whatever it decides it needs becomes the search. Not your query.
Here’s an example. You ask “what’s the best note-taking app?” ChatGPT doesn’t search for that. It thinks about what it needs to consider first. It might run searches like “best note-taking apps 2026” or, if you’d asked specifically about B2B, “B2B note-taking apps.” Those are the queries it actually runs.
And it doesn’t stop there. After the first round of searches, it reads what came back and figures out what else it needs. If it now has two frontrunners, its next search might be “Discord versus Notion” just to compare them. It reasons, searches, reasons again. Multiple steps.
The set of searches ChatGPT runs in the background is called query fanout. Most people either ignore it or take a lazy takeaway like "add 2026 to your title." But it's actually full of hints about what AI search is already trying to find.
Here's a real example. We searched "recommend best HR payroll software" in the ChatGPT. Here's what ChatGPT actually searched in the background:
- "best HR payroll software 2026 small business Gusto ADP Rippling Paychex BambooHR reviews"
- "Gusto payroll HR benefits official pricing 2026"
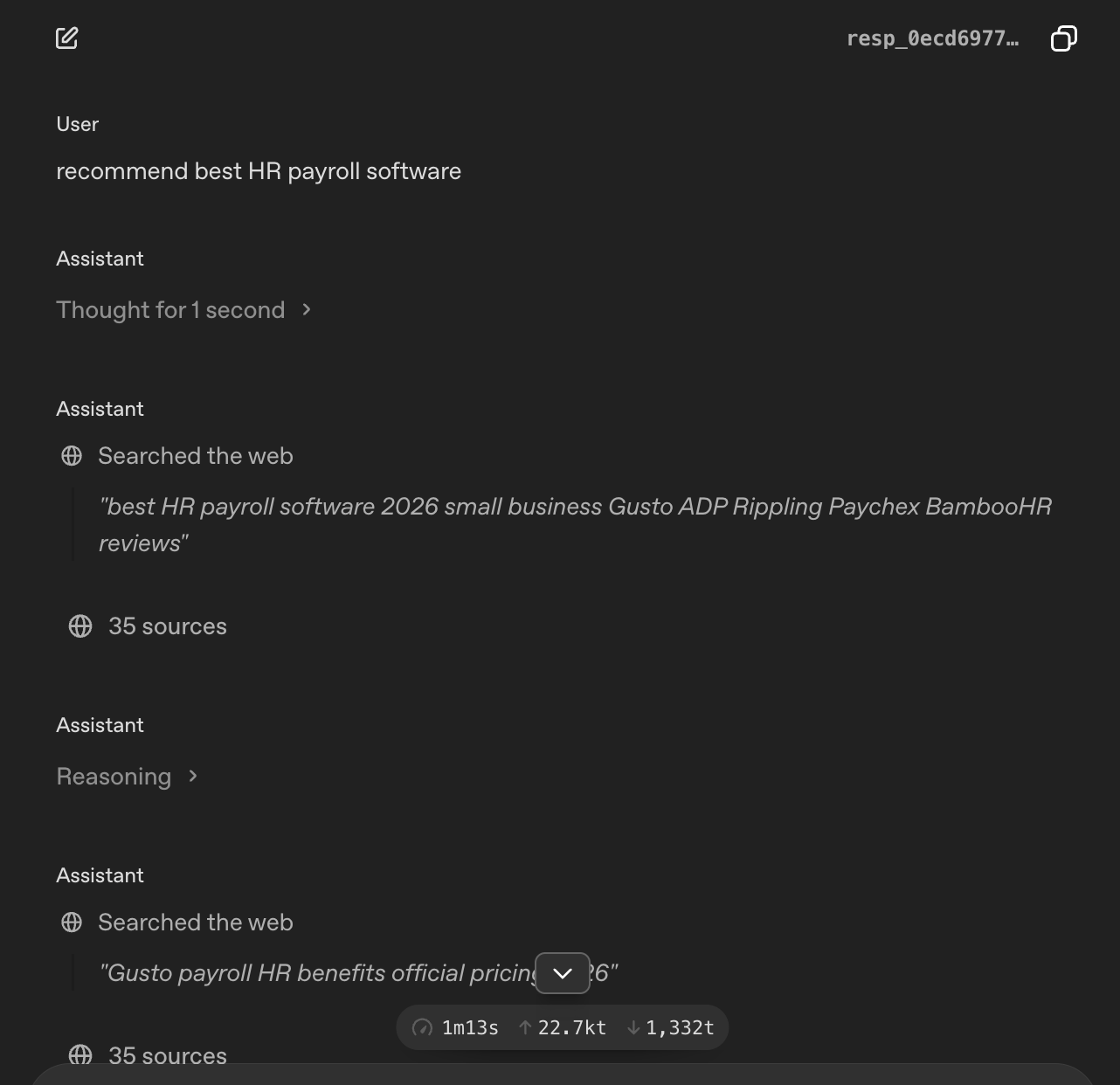
The user typed five words. ChatGPT searched for something completely different. And three things happened in that first background search alone.
It added criteria the user never typed. "Small business." "Reviews." "Pricing." Before reading a single page, ChatGPT had already decided what matters for this category.
It added company names the user never typed. Gusto, ADP, Rippling, Paychex, BambooHR. ChatGPT had already formed a shortlist before it searched anything. The search wasn't an open question. It was a confirmation exercise. It already knew who it was going to recommend, and it was now looking for proof.
It added the year "2026." It knows this is a buying decision and it wants recent data.
After those searches, it reasoned for a moment, then came back with: "Assuming you're a small-to-mid-sized business looking for HR + payroll in one system, my shortlist is..." and named those same companies.
This is what query fanout tells you. If your company isn't in those background searches, you weren't on the shortlist before ChatGPT read a single page. Getting there means changing what the model already believes, not just what it finds when it searches.
So let's say it searches and finds a page. What happens next? Does it read the whole thing? Does it skim? Does it read the first paragraph and move on?
That's what the next section is about.
4. How does ChatGPT read a page?
ChatGPT doesn’t read your page the way a human does. It uses a version of skimming. Here’s what we know about it so far.
First, ChatGPT decides whether your page is worth reading at all. It looks at your title and description, the same way you’d scan Google search results before clicking. If the title and description don’t match what it’s looking for, it might not read the page at all.
If it decides your page is worth reading, it doesn’t start from the top. Instead, it does something closer to a CTRL+F. It runs a fuzzy keyword match to land on a specific word or phrase on the page. Then it reads a few sentences above and below that word to get context. Based on what’s around it, it decides whether the rest of the page is worth reading further.
The main difference from how humans read: humans care about the start of a page. The intro. The hook. ChatGPT doesn’t.
An AI answer is essentially a summary of what the LLM found across many pages. It reads a bunch of sources and stitches together a single response. So if your page says the same things every other page in the category says, there’s nothing new for the LLM to pull from you. You don’t add to the summary, so you don’t get cited.
What gets pulled is the unique information your page adds. The piece that wasn't already covered by the other pages it read. Remember: ChatGPT doesn't read all pages at once. It searches and reads incrementally. Once it has pulled a fact from one source, it doesn't need to pull the same fact from you. If the market leader already said what you're saying, that information is already in the answer. Your page adds nothing new to the summary, so you don't get cited. Unique information is your way in..
You’ll hear advice like: add FAQs to every page because LLMs love them. Same with: add schema markup, use short paragraphs, generate an LLMs.txt file.
There's a kernel of truth in some of this. FAQs, for example, happen to fit how ChatGPT reads pages. They're built around question phrases that are easy keyword matches, with answers sitting right next to them. So FAQs do work, but for the wrong reason. Most people who recommend them don't actually know why.
But now that you do, you can do something smarter. Look at your query fanout. It tells you exactly what searches ChatGPT is likely to run in your category. Write content that directly addresses those searches, as proper information-dense paragraphs in your page, not as a separate FAQ section bolted on at the bottom. The mechanic is the same. The execution is better.
5. Which citations actually matter, and which don’t?
This is the most important question. It’s also the hardest to answer.
When ChatGPT gives you an answer, it shows citations. The natural assumption is that these are the sources it used to decide the answer. So if you want to influence the answer, you just need to get your brand onto those sources. That assumption is only partly right.
Some citations don’t influence the answer at all
Remember what we said earlier. ChatGPT often decides its answer first, and then does more searches to justify the decision it already made. So the citations you see at the bottom of an answer are a mix of two things: citations that helped it decide, and citations it added afterwards just to justify the answer or have something to link to. From the outside, these look exactly the same.
It can be even more extreme than that. Sometimes citations have nothing to do with the recommendation at all. BlackRock Asset Management showed up in answers about finance products even though it didn’t appear in any of the listicles ChatGPT cited. In this case, the brand came from training data. The citations didn’t drive the recommendation.
You can’t tell per-answer which citation was the important one
For any single answer, can we figure out which citations actually influenced it? Not reliably.
Here’s what we considered:
- Citation inside the answer vs. citation in the references. You might think the ones quoted directly in the answer matter more. But the opposite is also defensible: maybe those are the ones added at the end to justify a point. There’s no way to know which citation ChatGPT found first, so position isn’t a reliable signal.
- Frequency within a single answer. Doesn’t work either. Even within one answer, some citations carry more weight than others. If ten citations mostly say the same thing but three of them line up better with what ChatGPT already believes about the category, those three will influence the answer more than the other seven. Frequency within one answer doesn’t tell you about weight.
- Reasoning traces. The reasoning isn’t always shown, and when it is, it’s not reliable enough to pin influence on a specific citation.
So for any single answer, we can’t reliably say which citation did what.
What we can do instead
1. Use the nature of the page. Some types of pages are almost never used to make a decision. They're used to link to something or justify a point. Wikipedia pages are like this. Company homepages are like this. If ChatGPT cited a company's homepage, the homepage probably didn't drive the decision to recommend that company. It was just the link at the end. By the nature of the page itself, we can filter out a chunk of citations that don't matter. And yes, we're saying that just having a Wikipedia page is not nearly as important for AI search as influencers make it sound.
2. Compare recommendations on the page to recommendations in the answer. Take an answer that recommends some tools. Then look at the pages it cited. If the same tools show up on those pages, the citations probably influenced the answer. If a recommended tool doesn’t appear on any of the cited pages, that tool probably came from training data, not citations. BlackRock and Zoom are examples of this. A high overlap means citations mattered a lot. A low overlap means they mattered less.
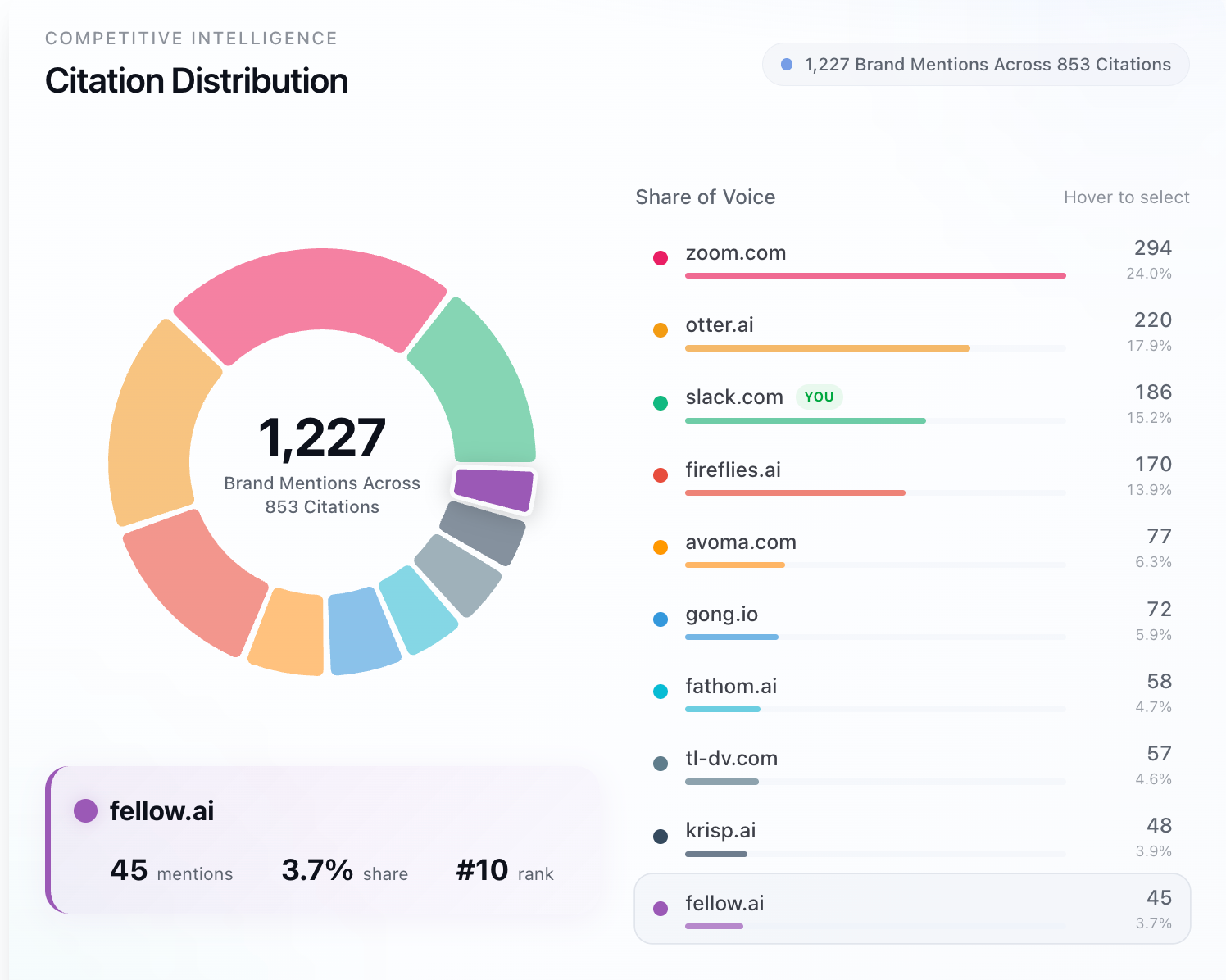
3. Look at frequency across many answers, not within one. This is the most important one. Forget which citation mattered for any single answer. Look across hundreds of answers in your category. If a page gets cited 50 times across different answers, it’s almost certainly influencing those answers. It’s very unlikely that a page gets cited that often without having some real influence on the recommendations.
Anything that shows up at the top of citations by frequency, across many answers, is almost certainly a useful citation. This is why Chosenly’s outreach feature groups citations by frequency. The stuff at the top of that list is where to spend your time.
6. Which companies get recommended?
Two things decide which companies ChatGPT recommends. How often they show up, and whether they fit the criteria.
Who gets recommended more often
This connects directly to what we said in the citations section. The companies that show up most frequently across citations in a category are almost always the ones getting recommended most often. Frequency of citations and frequency of recommendations move together. If you're consistently showing up in the pages ChatGPT references, you're consistently showing up in the answers it gives.
Who fits the criteria
Frequency gets you in the game. Criteria decide whether you win.
ChatGPT has beliefs about what matters in a category. You can see those beliefs in the query fanout. When it searches "best HR payroll software" and adds words like "pricing," "features," and "small business" to the background searches, those are the criteria it's already using to evaluate companies before it reads a single page.
Here's a real example of how this plays out. ChatGPT consistently recommends Darwinbox for HR tool searches. And the reason it gives, again and again across different answers, is the payroll feature. That tells you something important: out of everything ChatGPT knows about Darwinbox, payroll is what it has decided matters most for HR tool recommendations in that category.
If your product does payroll and your page doesn't say so clearly, you're not getting recommended for it. ChatGPT can't recommend you for a criterion it can't find evidence for.
If your product doesn't do payroll, you're not going to win on that criterion. But that's useful too. It tells you which criteria you need to find and own instead. Find the ones where no competitor has clearly staked a claim, collect objective proof that you're the best answer for it, and make sure that proof shows up wherever ChatGPT looks.
So can ChatGPT answers be influenced?
Yes. Here’s how.
Let’s bring it back to the original question. Can ChatGPT answers be influenced? Yes. But not the way most people are trying to do it.
Most teams jump straight into execution without understanding where they stand. They refresh content without knowing which pieces need it. They add FAQs and schema without understanding why those things work or whether they’re even the right lever for their situation. They do a lot of things that feel like progress but don’t actually move the needle.
A real GEO strategy starts with understanding where you actually stand today, and then figuring out the two or three things that will actually move the needle for your brand.
Here are the levers that work:
- Outreach: The single strongest predictor of how often an LLM recommends you is how often your brand appears in the pages those LLMs reference. Find the listicles and blogs in your category that already mention three or more of your competitors but not you. Those are your highest-confidence targets. Get placed on them.
- Content: Getting mentioned on other people's pages is one path. Creating your own pages that LLMs pull from directly is another. The content that gets referenced is in-depth, recently updated, and adds at least one unique insight that can't be found anywhere else. If your page says the same things every other page says, there's nothing new for the LLM to pull from you.
- Review sites: Most companies only invest in G2 and Capterra. LLMs pull from a much broader set. Get listed on the niche ones in your category. The bar is low. If everyone on a niche review site has three reviews and you get four, you're the top-ranked software on that platform.
- Reddit: In most B2B industries, Reddit is among the most referenced domains. Go through every thread in your category that's already being cited and make sure you're present in it. Then stay on top of new threads every week.
- Positioning: Getting found is not the same as getting chosen. LLMs don't just pick whoever shows up most often. They pick the company that best fits the criteria in the prompt. Find the criteria in your category where no competitor has clearly staked a claim. Collect objective proof that you're the best answer for it. Make sure that proof shows up on your website and in third-party sources.
The companies that win at GEO are not the ones doing the most. They're the ones who looked at their data, understood what's actually driving results in their category, and built a plan around that.
If you want the full step-by-step playbook, including how to read your data, how to prioritise between these levers, and exactly how to execute each one, read our GEO strategy guide.
Want us to create a GEO strategy for you?
FAQs
What does the "answer now" do on ChatGPT?
"Answer now" button is not on ChatGPT. That's a Gemini feature. On Gemini, pressing "Answer Now" skips the deep thinking and gives you a faster answer using a lighter model. ChatGPT doesn't have an equivalent button, though you can switch to a faster model manually.